Transformer
1 基础
1.1 Attention
这一阶段的核心是计算输入句子中各 token 之间的语义关系,为后续的 MLP 提供上下文信息。MLP 层则进一步判断输入句子与大规模文本数据之间的关联。
具体的原理不赘述,一种带 RoPE 的复现请参考个人仓库:
wall_e/model at develop · alan-tsang/wall_e · GitHub
Pad Mask:
用于屏蔽 padding token,使注意力机制在计算和 loss 时不考虑无意义的字符
| Batch / Token | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Batch 1 | 101 | 2054 | 2003 | 102 | 0 | 0 |
| Pad Mask 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| Batch 2 | 101 | 2129 | 2024 | 2017 | 102 | 0 |
| Pad Mask 2 | 1 | 1 | 1 | 1 | 1 | 0 |
- 1 表示有效 token,可参与 attention
- 0 表示 padding token,被 mask 掉,不参与 attention
- Shape 是(batch_size, len)
- 多头广播到(batch_size, 1,1,len)或者数据处理阶段广播
Look Ahead Mask:
用于 decoder 的自回归生成,保证每个位置只能看到当前位置及之前的 token,避免信息泄露。
- shape是 (batch_size, len, len)
- 多头注意力广播到 (batch_size, 1, len, len) 或者数据处理阶段广播
1.2 PKV
Past key value (PKV),是一种广泛被采用的推理加速算法,其通过存储已生成 token 的计算结果,减少重复计算来加速自回归生成,主要适用于 decoder 模型,是典型的以空间换时间。
- 原理:在训练阶段,我们通过 look ahead mask,一次性把整个序列输入并计算,然而在生成时我们不可能这样去做了。生成时,因为我们是自回归的,所以每次生成新单词时,可以复用前面生成单词的 K、V ,concat 起来做总的新 K、V
- 数据结构是 [[key, value] for _ range (layer)]
- 代码:
class DecoderLayerForCausalLM(nn.Module):
def forward(self, x, mask=None, past_key_value=None):
f1, past_key_value = self.attention(x, x, x, mask, past_key_value=past_key_value)
……
return y, past_key_value
class Decoder(nn.Module):
def forward(self, x, x_mask, past_key_values=None):
# 初始化past_key_values(如果未提供)
if past_key_values is None:
past_key_values = [None] * len(self.layers)
new_past_key_values = []
y_hat = x
for i, layer in enumerate(self.layers):
layer_past = past_key_values[i] if i<len(past_key_values) else None
y_hat, new_layer_past = layer(y_hat, x_mask, layer_past)
new_past_key_values.append(new_layer_past)
return self.norm(y_hat), new_past_key_values
Attention 部分过长,见wall_e/model/transformer/attention.py at master · alan-tsang/wall_e · GitHub
1.3 PreNorm 和 PostNorm
PreNorm 指的是先 norm,再做 attention / mlp 等;PostNorm 则是先attention / mlp,再 norm。
一般认为,PreNorm 训练更加稳定,效果会差一些;而 PostNorm 则是相反;为什么Pre Norm的效果不如Post Norm? - 科学空间|Scientific Spaces 中提到,PreNorm 相当于加宽了模型而损失了深度。
1.4 SwiGLU 代替 MLP
1.4.1 Swish
Swish 是一种更好的激活函数,其相对于 ReLU具备更好的表达能力
当 F.silu,这时函数图像是
---
title: Swish
xLabel: x
yLabel: y
bounds: [-5, 5, -5, 5]
disableZoom: 1
grid: true
---
Swish(x)=x/(1 + exp(-x))
- 负数部分的小区间内保留了一定的曲线激活能力
1.4.2 GLU
GLU 是 Gated Linear Unit 的缩写,是一种在神经网络中常用的 门控激活单元它的核心思想是用一个门控机制控制信息流,从而增加非线性表达能力。
1.4.3 SwiGLU
SwiGLU 的定义就是 GLU + Swish(即 SiLU)激活
实现代码:
class SwiGLU(nn.Module):
def __init__(self, dim, hidden_dim):
super(SwiGLU, self).__init__()
self.dim = dim
self.w1 = nn.Linear(dim, hidden_dim, bias=False)
self.w2 = nn.Linear(dim, hidden_dim, bias=False)
self.w3 = nn.Linear(dim, hidden_dim, bias=False)
def forward(self, x):
x1 = self.w1(x)
x2 = self.w2(x)
# 使用SiLU作为Swish激活函数,因为Swish(β=1)等价于SiLU
return self.w3(F.silu(x1) * x2)
1.5 RMSNorm 代替 LayerNorm
定义:
Root Mean Square (RMS), 均方根误差
其中,
好处:
- 与 LayerNorm 相比,仅对向量的数值进行标准化缩放,不影响向量间的相对关系,即不影响向量的角度, 不会失真
- 少了一次减法和
参数,更加精简稳定,适合大规模训练和混合精度训练,
1.6 RoPE 代替绝对位置编码
参见RoPE
1.7 位置编码外推
“位置编码外推”(positional encoding extrapolation)通常是指在 Transformer 或其它基于注意力的模型中,当输入序列长度超过了训练时的最大长度,模型能否正确处理 未见过的更长位置。
为什么会有“外推”问题?
Transformer 原版的 **位置编码(positional encoding)**有两类:
- 绝对位置编码:每个位置用一个固定向量表示(如
sinusoidal或 learned embedding)。 - 相对位置编码:用相对位置信息(如距离差)来辅助注意力计算。
问题:
- 训练时:模型只见过序列长度 ≤ L。
- 推理时:如果输入长度 > L,绝对位置编码(特别是 learned embedding)会超出训练范围,模型可能崩掉。
- 理想目标:让模型能外推到“更长序列”甚至无限长。
1.7.1 常见的外推方法
1.7.1.1 Sinusoidal Encoding
- 原始 Transformer(Vaswani et al. 2017)用的
sin, cos周期函数。 - 具有“可外推性”:因为 sin 和 cos 是无限周期函数,可以天然表示超出训练长度的位置。
- 但:模型是否能利用它,取决于训练习惯。有时在很长距离上会退化。
1.7.1.2 Rotary Position Embedding (RoPE)
- 出现在 RoFormer (Su et al. 2021),GPT-NeoX、LLaMA 等都用。
- 思想:把 query/key 映射到二维复平面,乘上旋转矩阵实现相对位置信息。
- 特点:天然支持 外推,因为旋转角度随位置线性增长,可以计算任意长位置。
- 局限:外推太远时会出现“旋转过快”导致退化。
1.7.1.3 ALiBi(Attention with Linear Biases)
- Press et al. 2022 提出。
- 在注意力分数里加入一个线性衰减偏置,随距离增加而降低。
ALiBi 在打分公式里 额外加入一个线性偏置项:
这样注意力会更关注相近的目标
- 优点:不需要显式位置向量,能很好外推。
- 缺点:编码能力较弱,适合语言建模但不一定适合需要精细位置信息的任务(如编程/数学)。
1.7.1.4 NTK Scaling(LLaMA-2 用)
- 解决 RoPE 外推“角度过快”的问题。
- 通过缩放 RoPE 的频率,让模型能稳定处理更长输入。
1.7.2 实际应用建议
- 要长序列外推 → 用 RoPE + NTK scaling/YaRN(现在大模型的主流选择,如 LLaMA-2, 3)。
- 追求最强外推 → 考虑 ALiBi,特别是只做语言建模的场景。
- 需要通用性(NLP + CV) → sin/cos 或相对位置编码依然是稳妥选择。
1.8 计算资源需求
模型的参数量:

占用显存推导:
Transformer Math 101 | EleutherAI Blog
1.9 QA
encoder一直都是并行的;decoder训练时并行,推理时串行。
decoder训练时为什么可以并行?原因在于teacher-force和look-ahead mask。
encoder self-attention中使用的是padding mask,其方法是将QK计算之后的padding位置的数字变为一个很小的数,这样在计算softmax后,padding位置的值会变为0,目的是为了使得注意力机制计算和 loss 计算时,不考虑padding的无意义字符。
decoder self-attention中使用的是look-ahead mask,其方法是将答案QK计算之后的注意力矩阵(如下图所示),进行遮掩,目的是在训练并行时遮掩使其看不到未来的信息,而预测 trg_y ,从而不泄漏答案。

合并后 token 彼此间的独立性丧失了,从而使得 token 的语义消失
句子长度的不一致;一个样本内的特征联系是很密切的;
一般假设 Q、K.T 512 的每一维度,均为正态分布,那么 QK 相乘后,sqrt (d_k) 可以将标准差又缩放至 1
具体计算:
为什么transformer qk之后除以根号dk
缩放 embedding,使其 embedding的编码空间和 positon 位置编码 相符合
1.9.1 补充
2 Encoder VS Encoder-Decoder VS Decoder
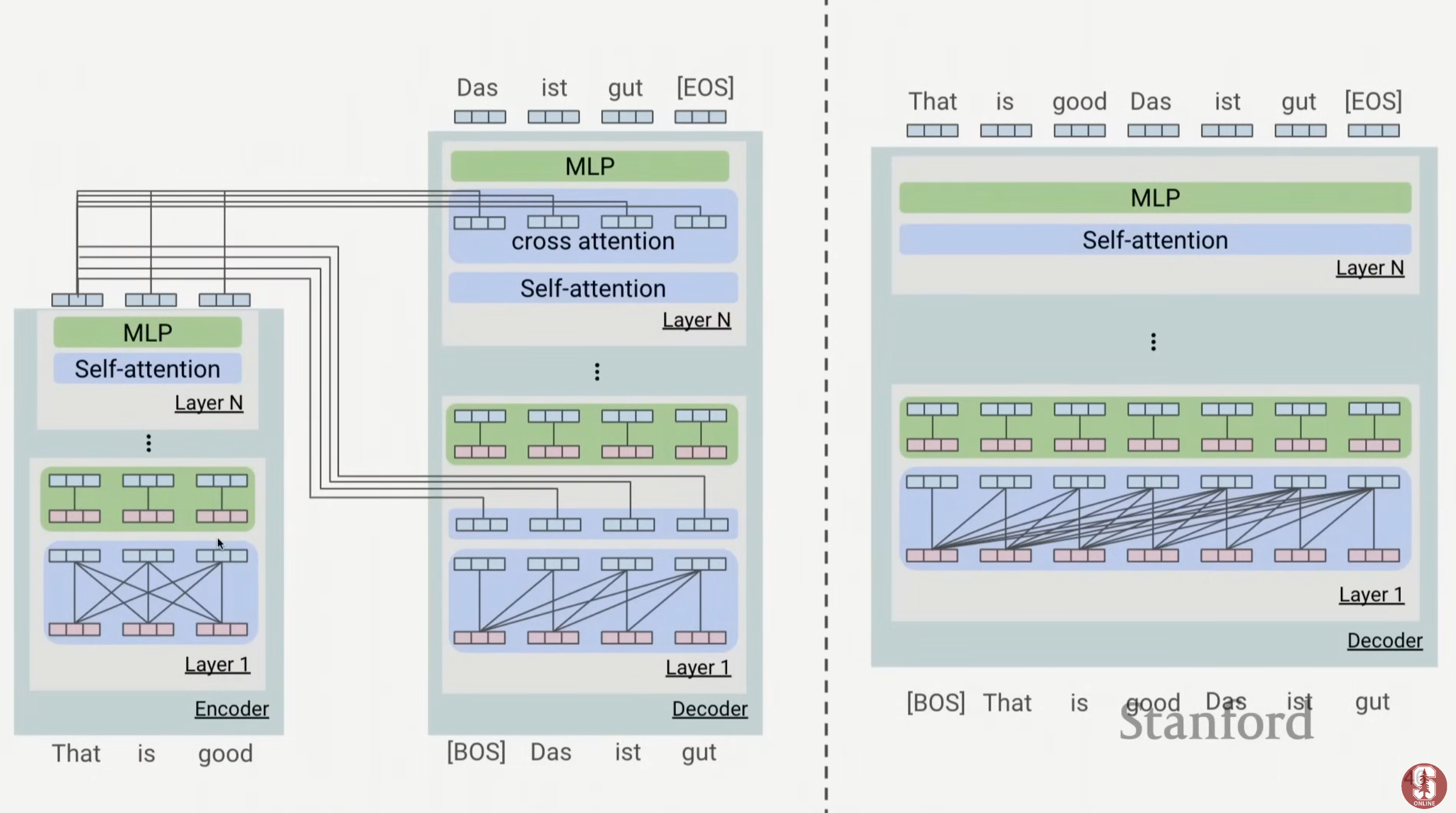

Encoder only :self-attention + no look ahead mask (bidirectional)
2.1 参考资料
Stanford CS25: V4 I Hyung Won Chung of OpenAI - YouTube 23:29
x.com
What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives — Yi Tay
3 Bert
三大创新点:mask training、trainable pos embedding、seg embedding
其中的seg embedding 基本被舍弃,没什么效果,另外trainable pos embedding 也被 RoPE 技术取代了,不是主流技术,但是其 mask training 是 encoder only 模型或者 encoder-decoder 模型训练的常用技术。
Mask Pretrain 实现代码如下:
def random_word(self, sentence):
tokens = sentence.split()
output_label = []
output = []
# 15% of the tokens would be replaced
for i, token in enumerate(tokens):
prob = random.random()
# remove cls and sep token
token_id = self.tokenizer(token)['input_ids'][1:-1]
if prob < 0.15:
prob /= 0.15
# 80% chance change token to mask token
if prob < 0.8:
for i in range(len(token_id)):
output.append(self.tokenizer.vocab['[MASK]'])
# 10% chance change token to random token
elif prob < 0.9:
for i in range(len(token_id)):
》output.append(random.randrange(len(self.tokenizer.vocab)))
# 10% chance change token to current token
else:
output.append(token_id)
output_label.append(token_id)
else:
output.append(token_id)
# 表示该tnk没有被mask-pretrain,那么就置零,不能是其他数字
for i in range(len(token_id)):
output_label.append(0)
# flattening
output = list(itertools.chain(*[[x] if not isinstance(x, list) else x for x in output]))
output_label = list(itertools.chain(*[[x] if not isinstance(x, list) else x for x in output_label]))
assert len(output) == len(output_label)
return output, output_label
self.criterion = torch.nn.NLLLoss(ignore_index=0)
or
self.criterion = torch.nn.CrossEntropy(ignore_index=0)
Mastering BERT Model: Building it from Scratch with Pytorch | by CheeKean | Data And Beyond | Medium
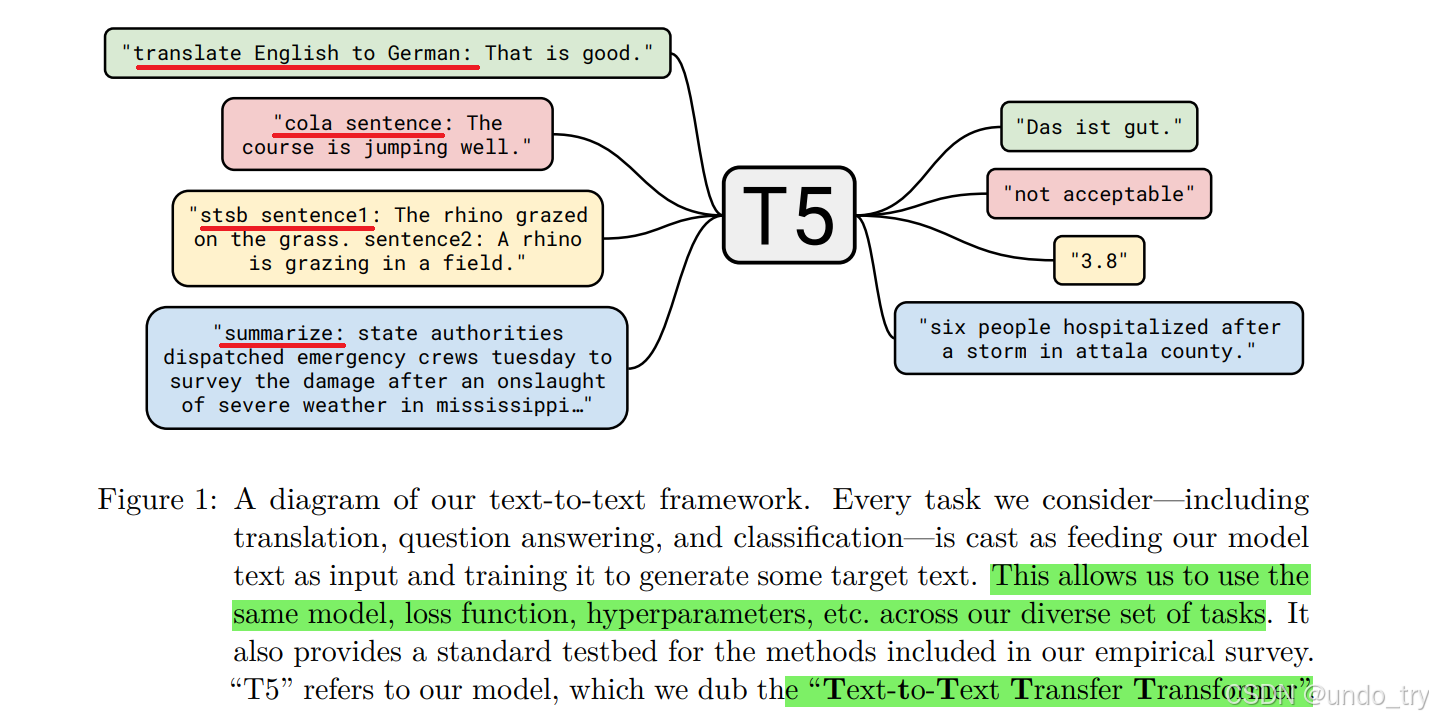
4 T5
- 我们知道BERT相关的预训练语言模型,在下游任务微调过程中都需要添加非线性层,将模型的输出转化为任务指定的输出格式。
- 但是,T5不需要对模型做任何改动,不需要添加任何非线性层,唯一需要做的就是在输入数据前加上任务声明前缀。
- 将翻译、分类、回归、摘要生成等任务都统一转成Text-to-Text任务,从而使得这些任务在训练(pre-train和fine-tune)时能够使用相同的目标函数,在测试时也能使用相同的解码过程。
5 transformer-XL
本文在于提高 transformer 上下文窗口,其核心技术改进是分段式循环 + 相对位置编码