RoPE
1 RoPE
旋转位置编码(Rotary Position Embedding, RoPE)是一种位置编码方法,广泛应用于 Transformer 架构中。它的核心思想是:
对输入向量的施加一个与位置相关的旋转变换,从而在注意力计算中,使得点积的结果中包含位置的相对差值
信息
理论推导: Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces
实现:

- q 对应隐藏层的向量;d 是隐藏层维度,会是 512,768……;m 对应 token 在序列中位置
- 实际应用中常采用指数式分布:
,以覆盖长短程不同的位置信息。 - 代码:
def sinusoidal_pos_embed(self, seq_len, dim):
"""
@return: (1, n, seq_len, dim) 完整的位置编码
"""
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2).float() / dim))
pos = torch.arange(seq_len, dtype = torch.float)
# will product
sinusoid_inp = torch.einsum("i,j->ij", pos, inv_freq)
sinusoid_pos = torch.stack([sinusoid_inp.sin(), sinusoid_inp.cos()], dim = -1).reshape(seq_len, -1)
sinusoid_pos = sinusoid_pos.unsqueeze(0).unsqueeze(0)
return sinusoid_pos.repeat(1, self.n, 1, 1)
def apply_RoPE(self, x, pos_id=0):
seq_len = x.shape[2]
pos_emb = self.sinusoidal_pos_embed[:, :, pos_id:pos_id + seq_len, :]
# cos_pos,sin_pos: (bs, head, max_len, output_dim)
# 看rope公式可知,相邻cos,sin之间是相同的,所以复制一遍。如(1,2,3)变成(1,1,2,2,3,3)
pos_emb = pos_emb.to(x.device)
# 将奇数列信息抽取出来也就是cos 拿出来并复制
cos_pos = pos_emb[..., 1::2].repeat_interleave(2, dim = -1)
# 将偶数列信息抽取出来也就是sin 拿出来并复制
sin_pos = pos_emb[..., ::2].repeat_interleave(2, dim = -1)
x2 = torch.stack([-x[..., 1::2], x[..., ::2]], dim = -1)
# reshape后就是正负交替了
x2 = x2.reshape(x.shape)
x = x * cos_pos + x2 * sin_pos
return x
- GitHub - ZhuiyiTechnology/roformer: Rotary Transformer
- wall_e/model/transformer/attention.py at master · alan-tsang/wall_e · GitHub
探讨:
- 外推支持非常好,因为旋转变换的角度支持
2 数学形式

(这里的 q 0,q 1实际上是实现中 q的 dim 隐藏层维度的 d1, d2)
给定输入向量的某个二维子空间:
在位置
其中,
旋转后的 Query/Key:
旋转后的 Query/Key 内积如下,嵌入了相对位置信息:
注意:以上的过程固定了幅角
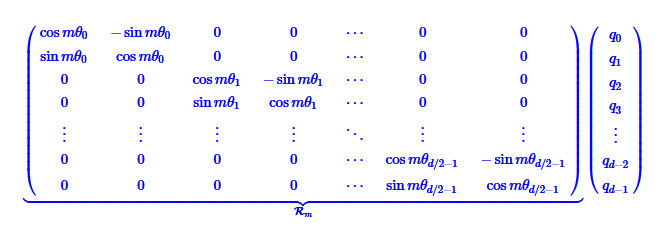
将
整体编码:
内积如下,只依赖相对位置:
注意:这意味着,对于不同位置的 token,例如 len 1, len 2 位置的(对应于 n,m),它们对应的向量进行内积,d 1,d 2 维度的幅角相同(q 0, q 1),d 3,d 4 维度(q 2, q 3)的幅角相同,……, 也就是两两分组包括了相对位置信息在其中
2.1 推导
2.1.1 事后精简版
证明引入复数的幅角,即旋转矩阵,可以使得内积的结果包含了相对位置信息。
我们将二维向量
于是两个位置
显然只依赖于
2.1.2 作者思路版
Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces
作者首先假定运算
同时也自然有
因为
考虑
这里作者为了简便,直接令
性质奇妙的地方来了,作者考虑以复数指数的形式进行求解(任何一个复数都可以用指数形式表示),将
其中,
因为 (5) 式的直接相等,所以实部等于实部,虚部等于虚部,注意(5)式的*表示共轭取反,因此有
令 m = n = 0, (7)-1 有
令 m = n,(7)-1 有
注意到(2)式,所以
也即
这说明两者的实部与 m 无关,也就是和位置无关,我们可以不关注这一项了
现在我们来看 (7)-2 式,令 m = n = 0, (7)-2 有
令 m = n,(7)-2 有
注意到(2)式,所以
也就是
因此
这意味着
代入
由(7)(8)(9)式整理可得:
注意到等式的右边全部和 m 无关,可以认为是一个和 q, k 相关的常数,这意味着
