Fine-tunning
1 hard, soft fine-tuneing
hard:Hard Prompt通常指的是一种明确的、固定的提示方式,通常以文本的形式直接输入给模型。
soft:向模型中添加参数,像 token embed 中加入可学习向量等方式实现的。
Soft Prompt通过调整模型的内部参数(即Prompt向量)来引导生成过程,而不是直接给出文本提示。这使得生成过程更加灵活和可学习。
1.1 prompt-tuning (soft)
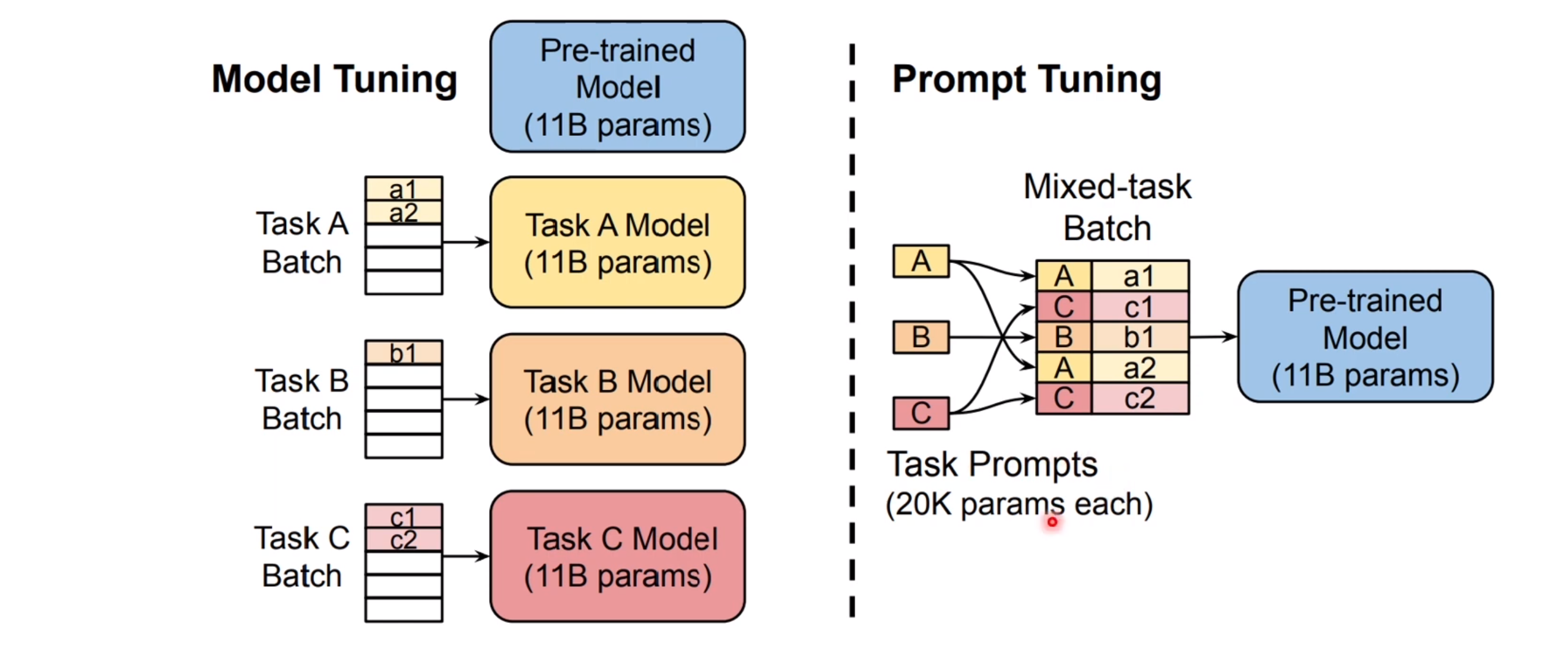
多子任务微调,左图式分别微调,右图是多子任务 soft prompt tuning
2 p-tuning
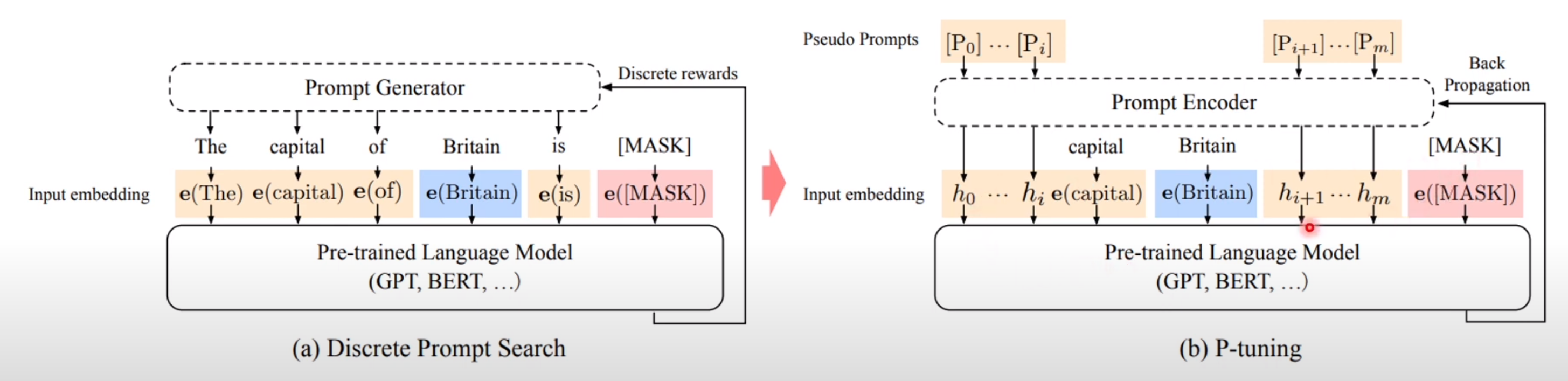
左图是硬编码 prompt 注入,右图是 p-tuning 注入的方式,其 prompt encoder 具体是下面的做法
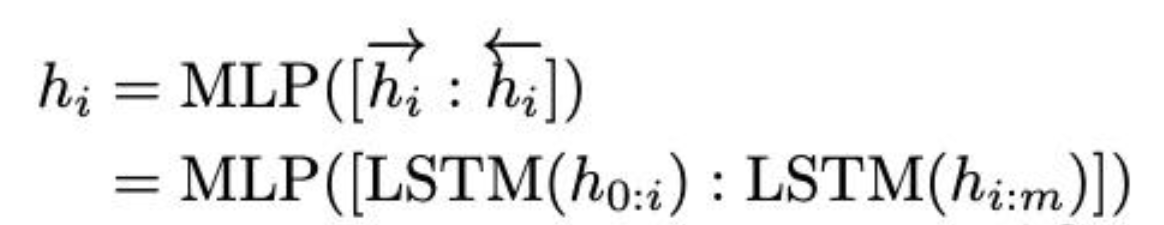
特点:
- 加了可微的virtual token,但是仅限于输入,没有在每层加;
- virtual token的位置也不一定是前缀,插入的位置是可选的。
- 用LSTM+MLP去编码这些virtual token以后,再输入到模型
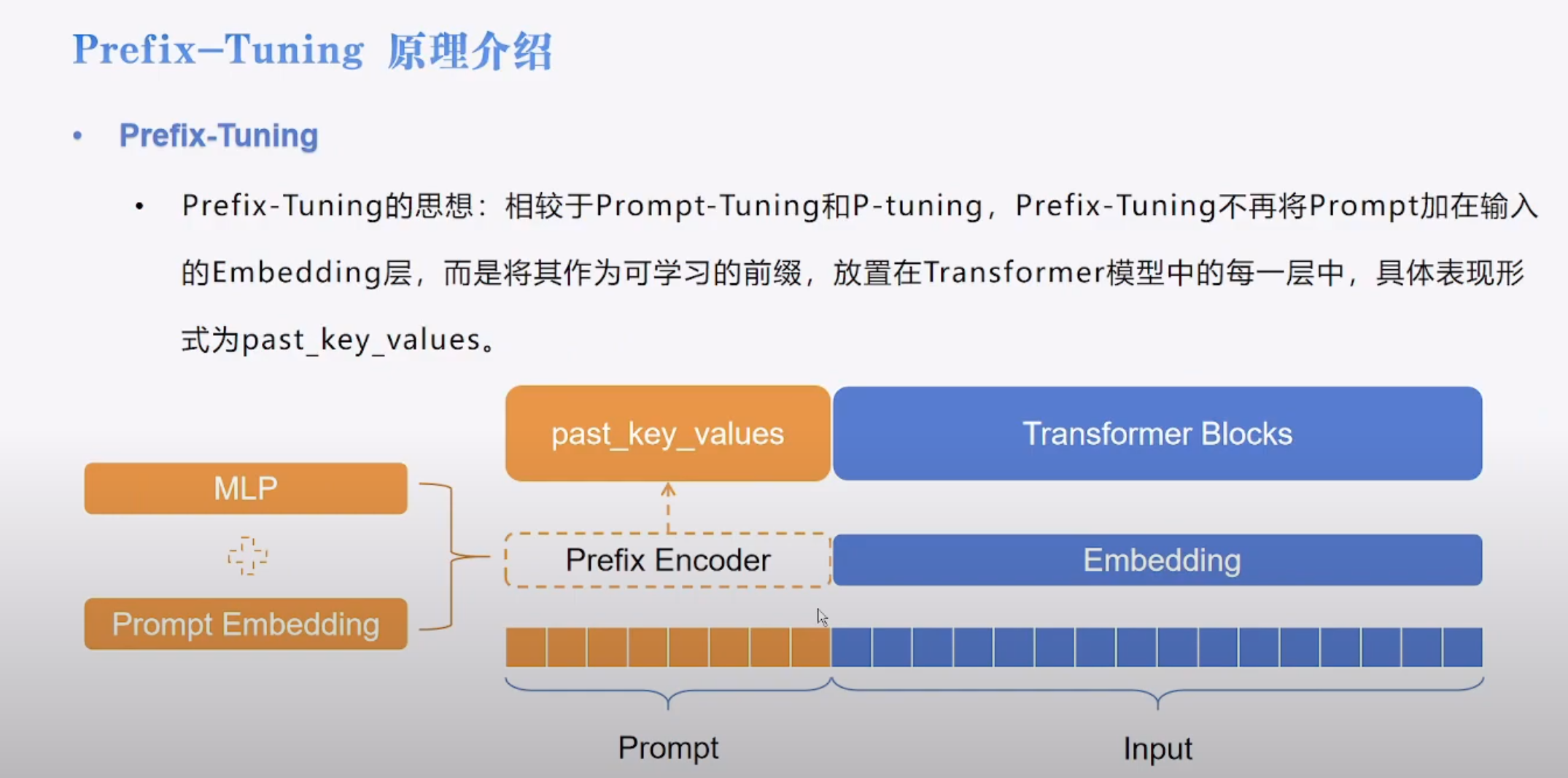
3 prefix-tuning
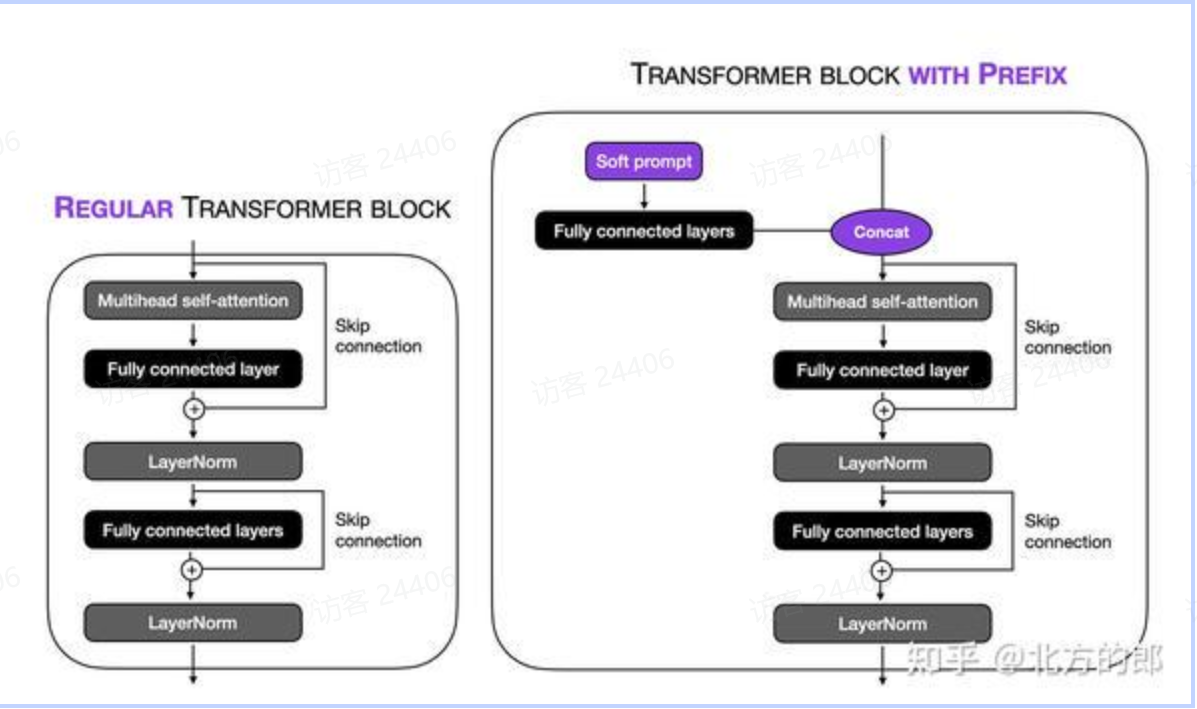
前缀调整的想法是向每个 Transformer 块添加可训练的 MLP,而不是像在软提示调整中那样仅向输入嵌入添加。上图说明了常规转换器块和使用前缀修改的转换器块之间的区别。
伪代码如图所示。
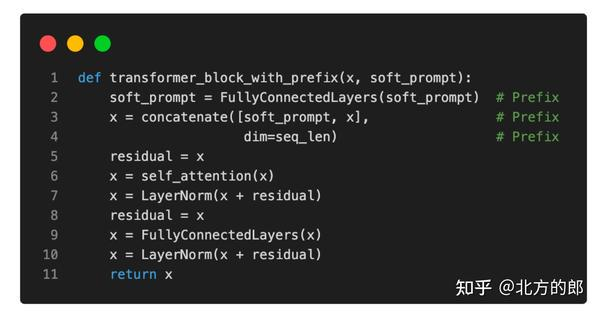
前缀微调的特点:
- transformer 的每一层都加入了 prefix
- prefix 是离散的 vec,属于 soft tuning
- prefix-encoder 外面套了一层 MLP
- 使用了 past_key_value 将 prefix 嵌入到 attention 中。
添加上去的实现方式可以使用 pkv:

3.1 效果关注点
可以降低参数
根据论文实验结果,对于**任务比较有效
不添加额外的模型层,但是 prefix_encoder 可能会带来推理延迟
3.2 参考资料
【手把手带你实战HuggingFace Transformers-高效微调篇】Prefix-Tuning 原理与实战 - YouTube
Continuous Optimization:从Prefix-tuning到更强大的P-Tuning V2 - 知乎
Transformers 官方 bloom 库(past_key_value)

4 LoRA Tunning
基本思想:大模型的参数量是冗余的,支持矩阵分解
Code LoRA from Scratch - a Lightning Studio by sebastian
矩阵分解论文分享20240613_哔哩哔哩_bilibili