Transformer
1 original transformer
1.1 生成时加速
past_key_value,见AtomFire的X/trick:\\wsl.localhost\Ubuntu\home\alan\desktop\project\AtomFire\demo\X\trick\past_key_value.ipynb

每次生成一个单词,复用前面生成单词的 K、V ,concat 起来做总的新 K、V
1.2 professor limu实现细节
- paddinmg mask数据格式分为有batch和无batch,有batch就是下图所示,第一个batch的两句话,有效长度分别是1和3,第二个则是2和4。
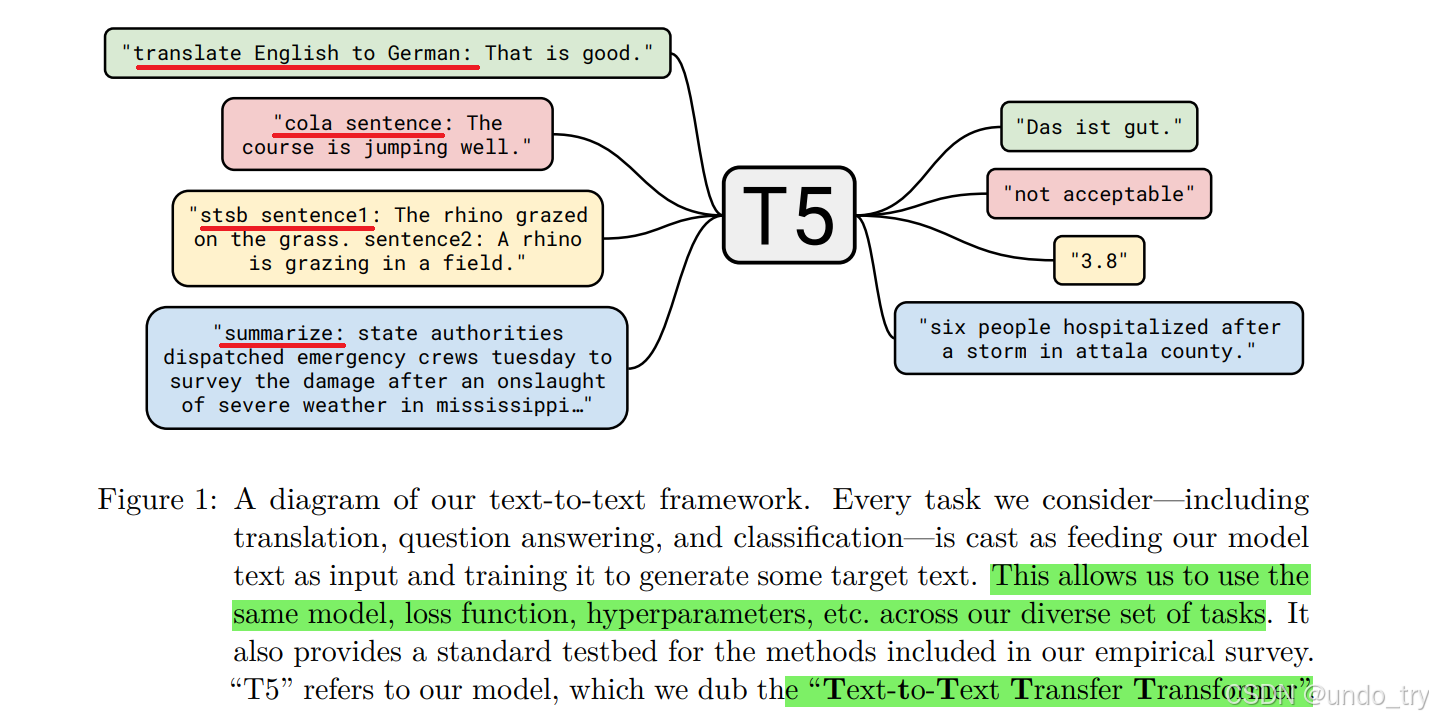
无batch会做一个复制操作,认为每一个batch的每一句话有效长度是一样的。 - 训练和预测时是分开的,训练时输入是预测监督标签的整句话,如下图1所示,而预测用的是一个一个的预测单词,如图2所示。
值得说明的是,key_padding_mask本质上是遮住key这个位置的值(置0),但是 token本身,也是会做qkv的计算的,以第三行数据的第三个位置为例,它的q是的embedding,k和v分别各是第一个的‘a’和第二个的‘b’,它也会输出一个embedding。
所以你的模型训练在transformer最后的output计算loss的时候,还需要指定ignoreindex=pad_index。以第三行数据为例,它的监督信号是[3205,1890,0,0],pad_index=0 。如此一来,即便位于的transformer会疯狂的和有意义的position做qkv,也会输出embedding,但是我们不算它的loss,任凭它各种作妖。
训练时每一次预测,第一个start预测下一个I, I预测下一个 am 以此类推。这样,最后就能生成一个len的句子。所以,实际上需要像LSTM那样有一个tgt_y_front、tgt_y_end。
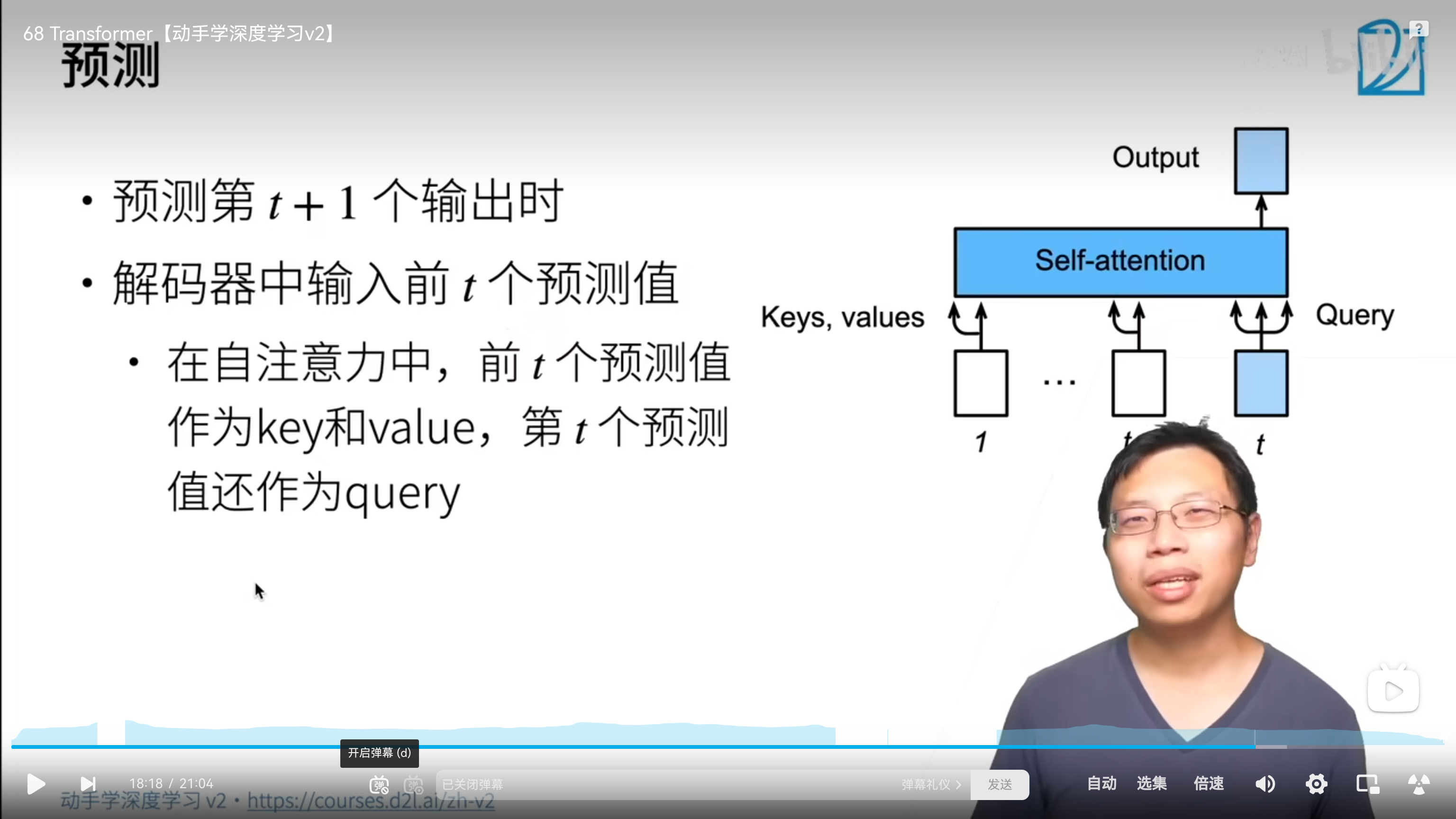
- 预测用的是之前全部的预测值作为key、value,而query则是第t个预测值。
1.3 广播实现的绝对位置编码相加
>>> x = torch.randn((16, 256, 512))
>>> y = torch.randn((512, 512))
>>> y = y.unsqueeze(0)
>>> (x + y[ : , : x.shape[1]]).shape
torch.Size([16, 256, 512])
1.4 mask实现语法涉及的广播机制学习
mask 机制的实现:
其中的10表示 hidden_size,2,3,4 实际的元素个数等价于hidden前面的,也就是 b, l, h
import torch
x = torch.arange(10)[None, :]
y = torch.tensor([2,3,4], dtype=torch.int32)[:,None]
mask = x < y
print(mask)
涉及到torch 广播机制。x < y 时,x (1, hidden_size) y (number, 1)
y会将1变为hidden_size,沿着最里面的行复制,具体如下:

x会复制number份
import torch
x = torch.arange(10)
# 手动进行广播 # 扩展 x 的形状以匹配 y 的形状
y = torch.tensor([2,3,4], dtype=torch.int32)
x_broadcasted = x.repeat(3, 1)
y_broadcasted = y.unsqueeze(1).repeat(1, 10)
print("\nManually Broadcasted x:")
print(x_broadcasted)
print("\nManually Broadcasted y:")
print(y_broadcasted)
mask_Manually = x_broadcasted < y_broadcasted
print(mask_Manually)
print(torch.equal(mask, mask_Manually))
1.5 Stanford NLP实现细节
概要
- 按照输入输出逻辑去搭建框架很合理
- 依赖注入,充分解耦,模型可变部分基本都是参数
- 代码紧凑,基本没有重复代码(通过clones函数和sublayerConnection函数)
- run_epoch和make_model的exact很好,适合不同的任务
- 没有显式说明输入数据的要求
- 整体框架没有明显区分开,可以结合atomfire去把训练框架做的更完美
具体
- 编码器和解码器框架,定义了子模块参数和之间的连接方式,且不同于limu老师的耦合,其forward过程在训练和预测时也还是统一的,适合作为net进行复用。
- 数据流动方面:(batch, seq_len) -> mask (batch, 1, seq_len),mask之后
- padding_mask时详细的过程
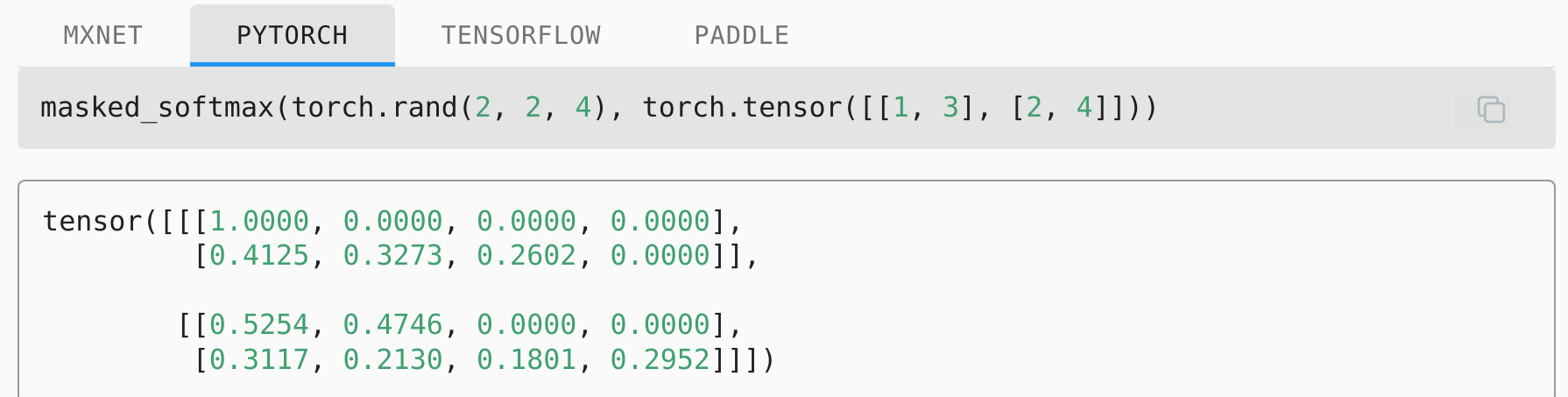
每一个头、len中的每一个,的每一个hidden,都使用广播的同一个mask、函数是masked_fill。
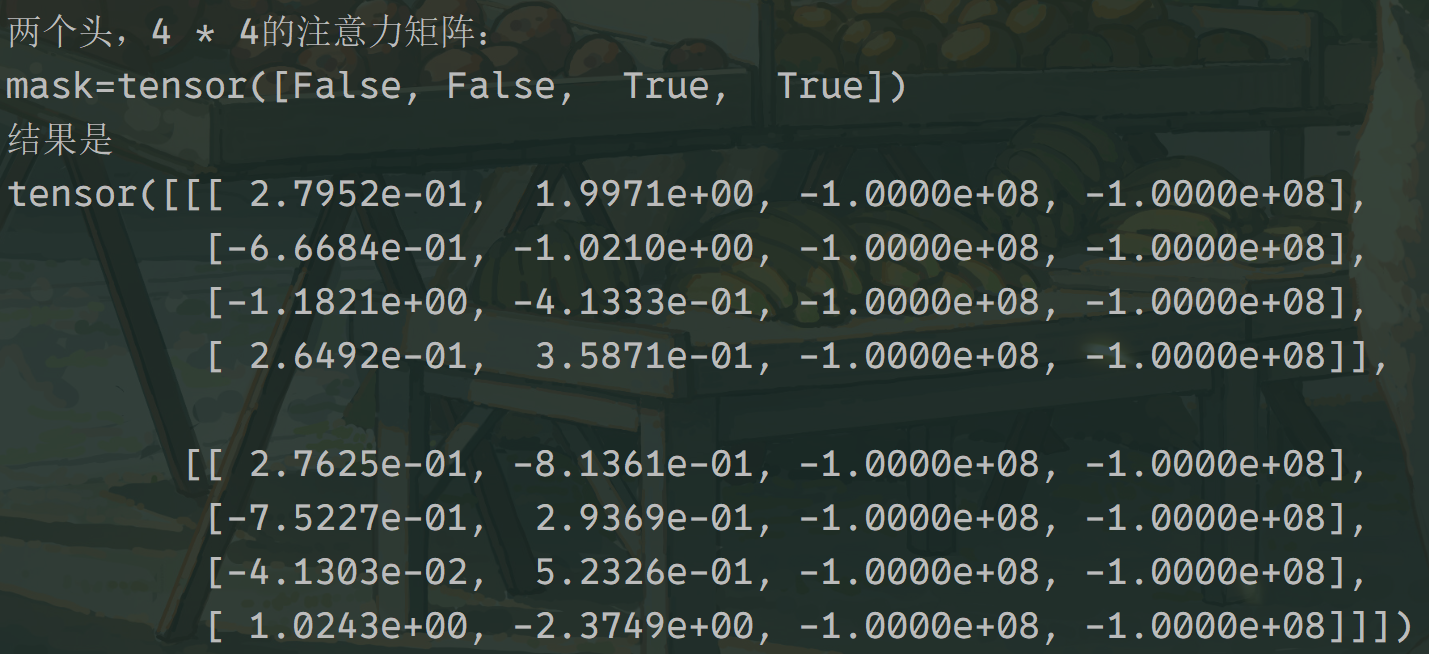
这样,后面的F.softmax(x, dim = -1)就可以保证每一个头的注意力矩阵都进行全部的归零。
1.6 问题
encoder一直都是并行的;decoder训练时并行,推理时串行。
decoder训练时为什么可以并行?原因在于teacher-force和look-ahead mask。
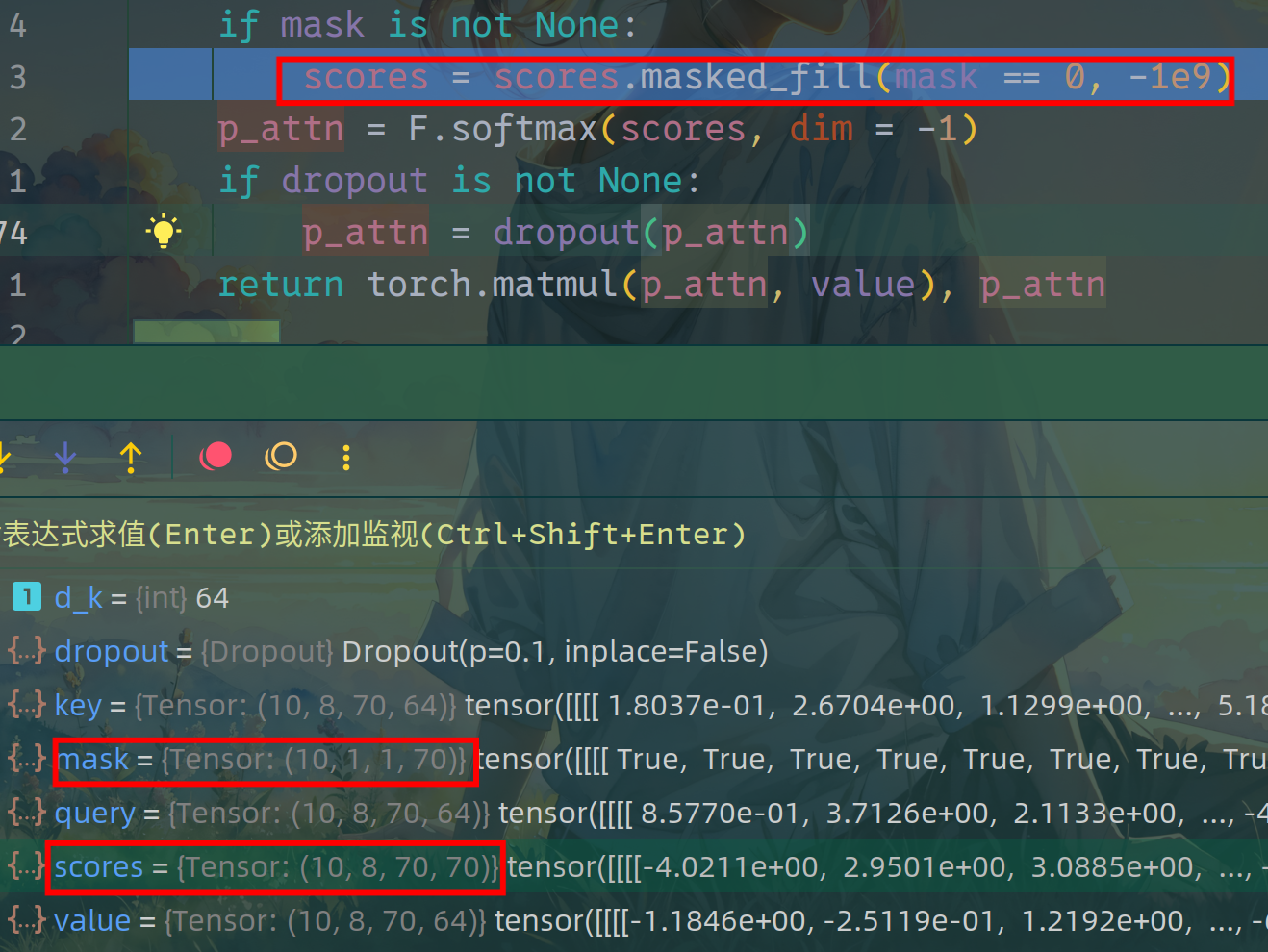
encoder self-attention中使用的是padding mask,其方法是将QK计算之后的padding位置的数字变为一个很小的数,这样在计算softmax后,padding位置的值会变为0,目的是为了使得注意力机制计算和 loss 计算时,不考虑padding的无意义字符。
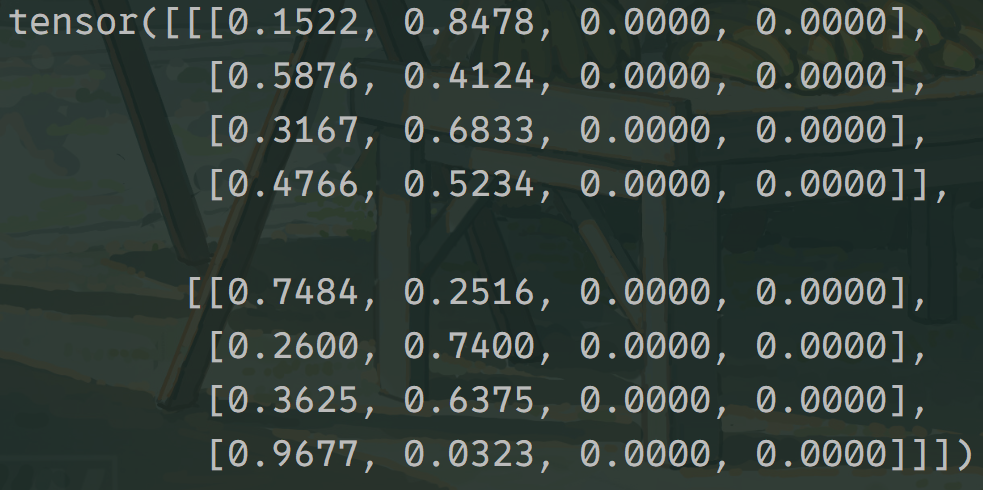
decoder self-attention中使用的是look-ahead mask,其方法是将答案QK计算之后的注意力矩阵(如下图所示),进行遮掩,目的是在训练并行时遮掩使其看不到未来的信息,而预测 trg_y ,从而不泄漏答案。

合并后 token 彼此间的独立性丧失了,从而使得 token
OK
句子长度的不一致;一个样本内的特征联系是很密切的
一般假设 Q、K.T 512 的每一维度,均为正态分布,那么 QK 相乘后,sqrt (d_k) 可以将标准差又缩放至 1
具体计算:
为什么transformer qk之后除以根号dk
缩放 embedding,使其 embedding的编码空间和 positon 位置编码 相符合

1.6.1 补充
2 Encoder-Decoder VS Decoder only
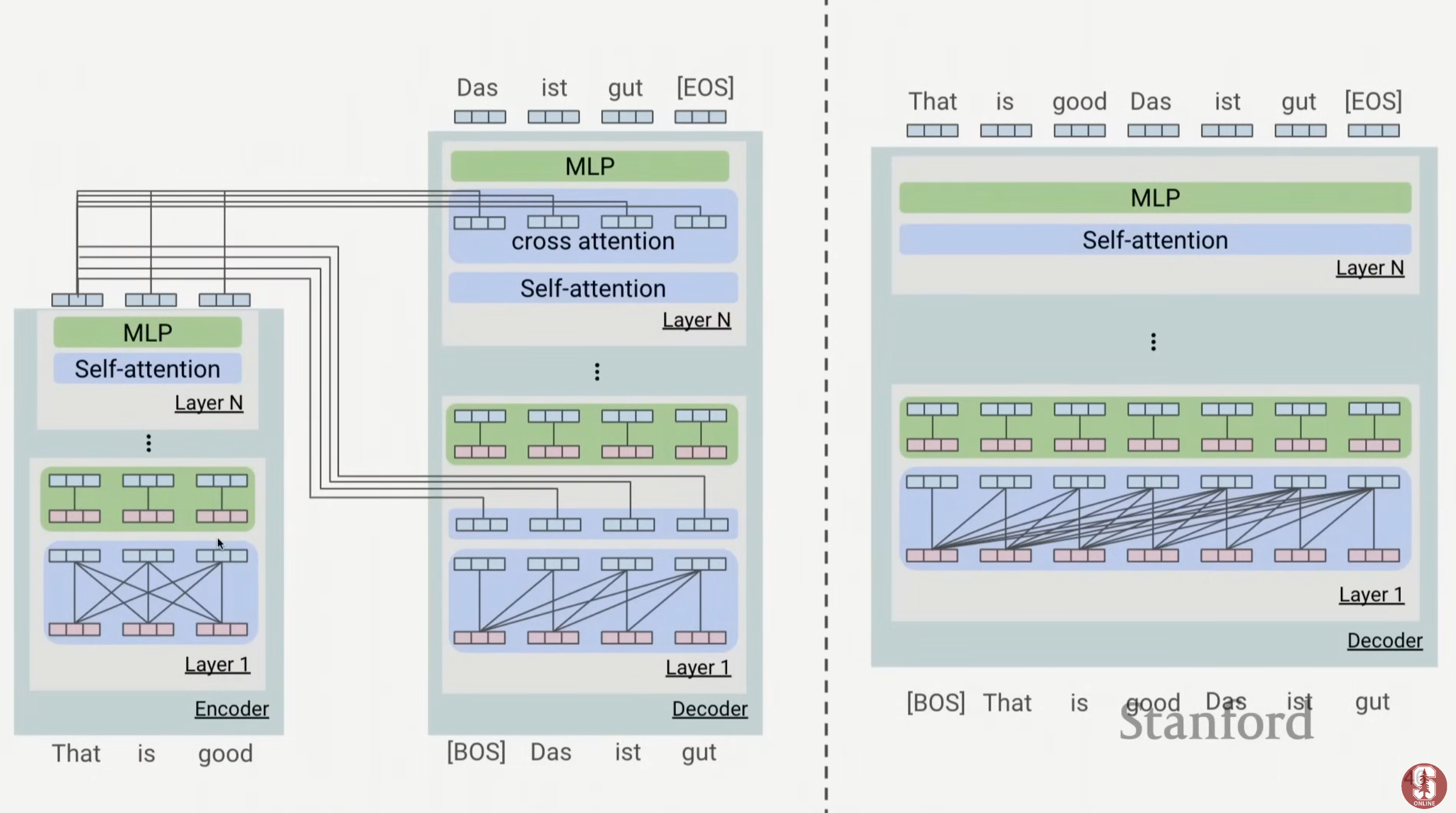

Encoder only 就是只有 self-attention 和
典型例子:Bert( mask training、trainable pos embedding、seg embedding)
2.1 参考资料
Stanford CS25: V4 I Hyung Won Chung of OpenAI - YouTube 23:29
x.com
What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives — Yi Tay
3 RoPE
旋转编码

公式推导中,(8) 式的推导过程:
整理且按照 (5) 式第二子式,即可得到 (8) 式
在θiθi的选择上,我们同样沿用了Sinusoidal位置编码的方案,即θi=10000−2i/dθi=10000−2i/d,它可以带来一定的远程衰减性。
GitHub - ZhuiyiTechnology/roformer: Rotary Transformer 提供了旋转位置编码的实现
4 Bert
Mask-pretrain 核心代码如下:
def random_word(self, sentence):
tokens = sentence.split()
output_label = []
output = []
# 15% of the tokens would be replaced
for i, token in enumerate(tokens):
prob = random.random()
# remove cls and sep token
token_id = self.tokenizer(token)['input_ids'][1:-1]
if prob < 0.15:
prob /= 0.15
# 80% chance change token to mask token
if prob < 0.8:
for i in range(len(token_id)):
output.append(self.tokenizer.vocab['[MASK]'])
# 10% chance change token to random token
elif prob < 0.9:
for i in range(len(token_id)):
》output.append(random.randrange(len(self.tokenizer.vocab)))
# 10% chance change token to current token
else:
output.append(token_id)
output_label.append(token_id)
else:
output.append(token_id)
# 表示该tnk没有被mask-pretrain,那么就置零,不能是其他数字
for i in range(len(token_id)):
output_label.append(0)
# flattening
output = list(itertools.chain(*[[x] if not isinstance(x, list) else x for x in output]))
output_label = list(itertools.chain(*[[x] if not isinstance(x, list) else x for x in output_label]))
assert len(output) == len(output_label)
return output, output_label
self.criterion = torch.nn.NLLLoss(ignore_index=0)
or
self.criterion = torch.nn.CrossEntropy(ignore_index=0)
Mastering BERT Model: Building it from Scratch with Pytorch | by CheeKean | Data And Beyond | Medium
5 transformer-XL
分段式循环 + 相对位置编码
6 realformer
融合了Pre-Norm 和 Post-Norm ,加了个残差
7 Funnel-Transformer
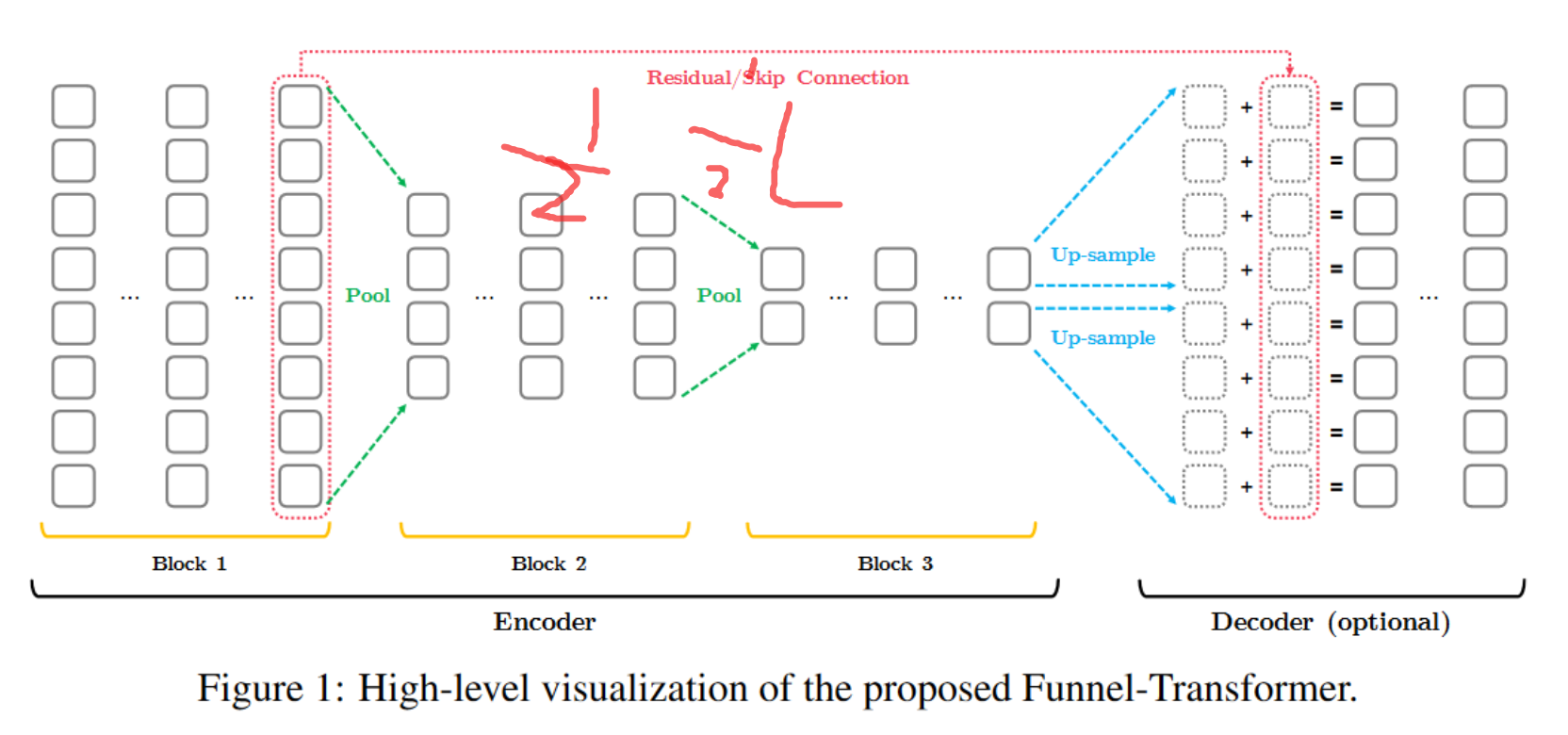
轻量级 transformer:使用池化降低参数量,decode 首先上采样,
8 T5
- 我们知道BERT相关的预训练语言模型,在下游任务微调过程中都需要添加非线性层,将模型的输出转化为任务指定的输出格式。
- 但是,T5不需要对模型做任何改动,不需要添加任何非线性层,唯一需要做的就是在输入数据前加上任务声明前缀。
- 将翻译、分类、回归、摘要生成等任务都统一转成Text-to-Text任务,从而使得这些任务在训练(pre-train和fine-tune)时能够使用相同的目标函数,在测试时也能使用相同的解码过程。