Contrastive Learning
1 参考资料
2 引言
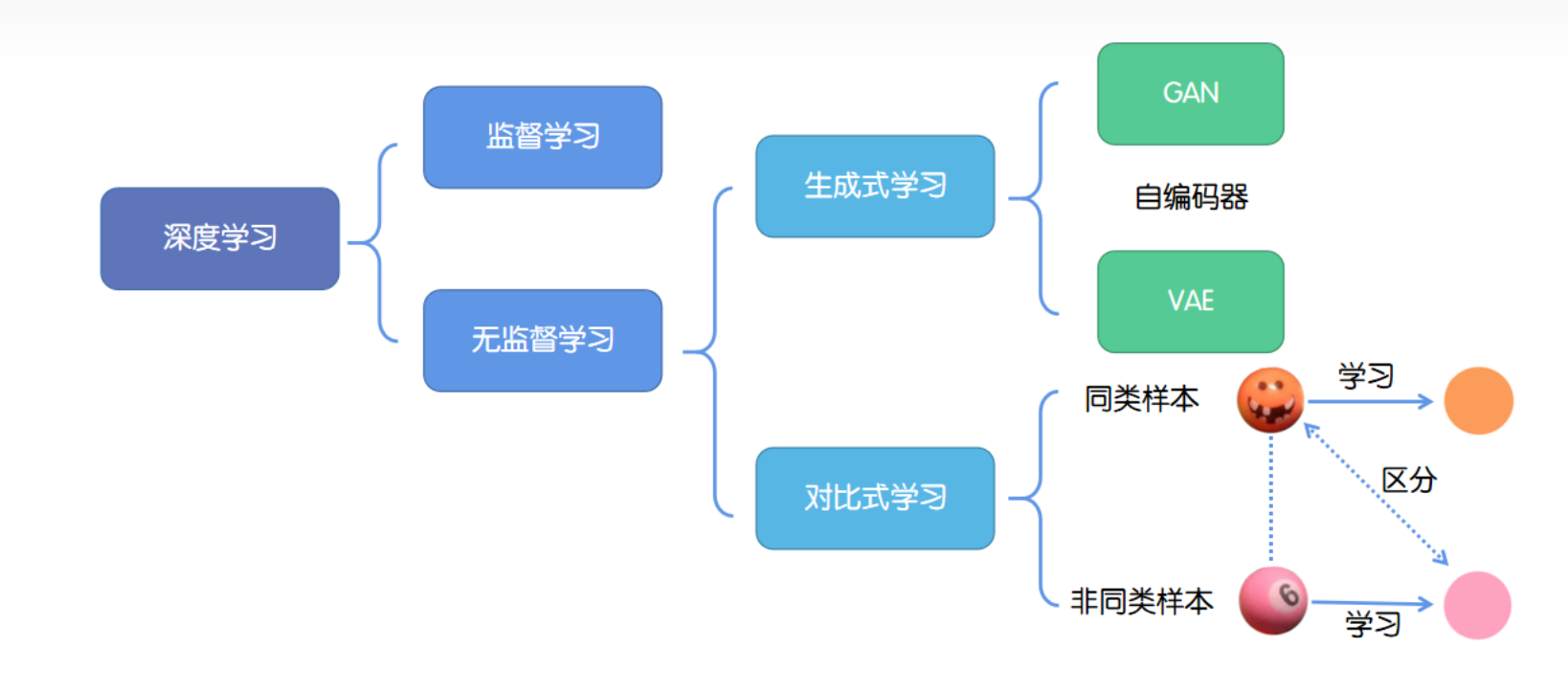
对比学习(Contrastive Learning)是深度学习中一种重要的学习方式,从计算机视觉领域(2018年)发展而来,特别在半监督学习和无监督学习中得到广泛应用。它的核心思想是通过比较样本对之间的相似性和差异性来学习数据的表示。
通常,对比学习通过构建正负样本对来进行,其中相似的样本被视为正样本,不相似的样本被视为负样本。对比学习的算法被训练以最大化相似数据点之间的相似度,并最小化不相似数据点之间的相似度。
对比学习最常用的基本模型架构是孪生网络和动量自编码器。孪生网络使用一对相同的神经网络来学习数据点之间的相似度函数,从而实现对数据的有效表示。
随着对比学习领域的蓬勃发展,众多经典研究不断涌现,令人瞩目的是,现在甚至可以在不依赖负样本的情况下进行对比学习。
此外,对比学习的灵活性和通用性使其能够与众多研究工作无缝结合,例如多模态、蒸馏、多视角、CV、NLP等等。
3 简介
本节,将大体按照论文的发表顺序,对对比学习的标志性论文进行简要的梳理。
本节目的是,了解对比学习的基本特点,脉络,适用任务。
3.1 InstDisc
Short of Instance Discrimination
3.1.1 基本信息
原文名称:Unsupervised Feature Learning via Non-Parametric Instance Discrimination。
2018年 CVPR,Zhirong Wu 华人 3567 Citation 加州伯克利

3.1.2 主要思想
- 同一分类的图片,之间的相似度本来就比较高,并不是因为有同一语义标签。这就意味着标签不是不可或缺的。
- 把每一张图片都看成一个类别,进而推出了个体判别的任务。
- 目标,学到一种特征,把每一张图片彼此区分开。
3.1.3 技术细节
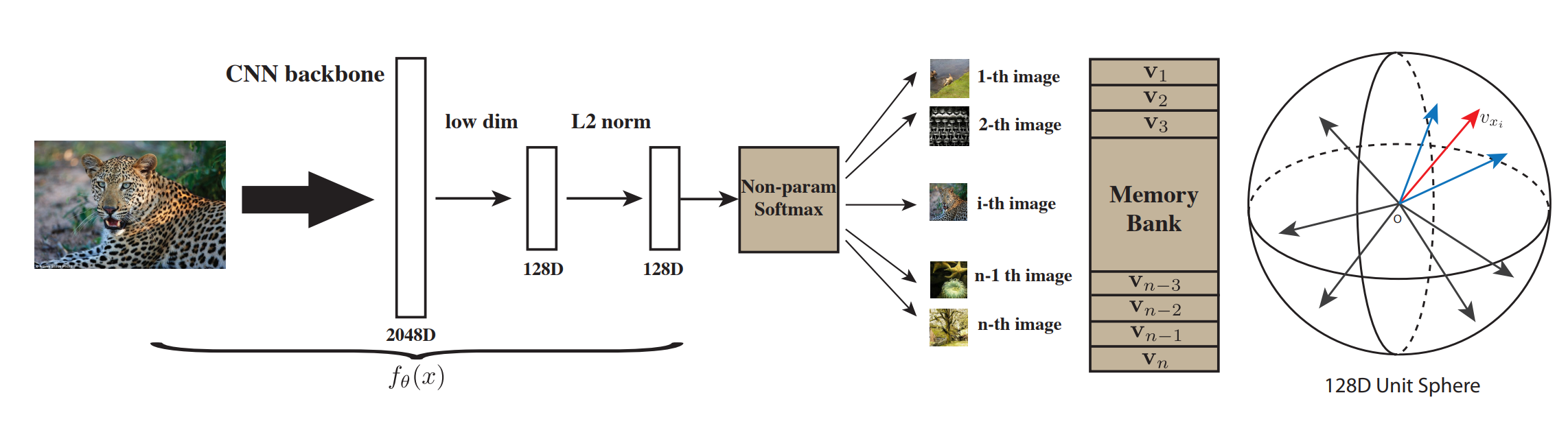
- memory-bank中存储的是负样本(128万张图片 * 128维度特征),原文抽了4096个,也就是正样本:负样本 = 1: 4096
- NCE loss,温度设置的是0.07
- memory bank,这里在每一个epoch后,里面存储的特征全部更新
- 超参数设置:200epoch,0.03 lr,batch_size = 256
- 一种数据结构,用来存储 memory bank
3.2 InvaSpread
原文名称:Unsupervised Embedding Learning via Invariant and Spreading Instance Feature。
2019年 CVPR ,Mang Ye 华人 cia 571 香港浸会大学(QS 290)

3.2.1 主要思想
- 基于个体判别任务
- 不用memroy bank,端到端
3.2.2 技术细节
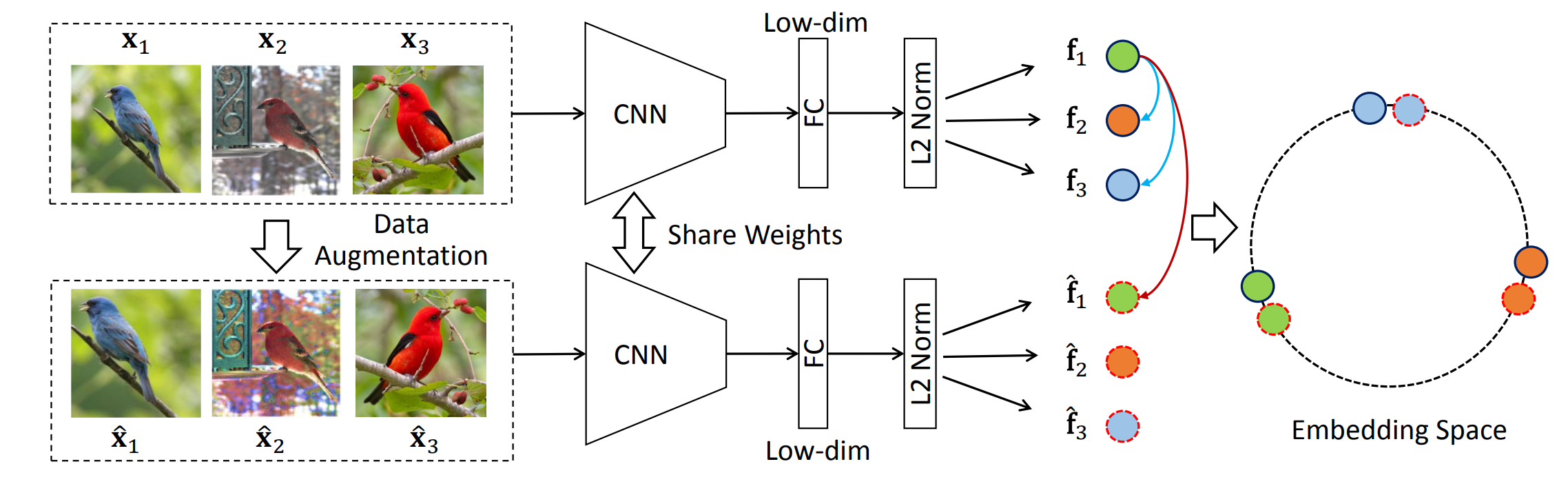
- 孪生编码器
- 没有额外的数据结构,存储负样本这一过程
- 每一个minibatch中,彼此(包括数据增强之后的图片)进行对比学习
- 本文batch_size 256,考虑一一对应的数据增强,正负样本比是
。 - 最后的结果不是很炸裂
3.2.3 意义
- simCLR的前身,只是缺少MLP Projection、数据增广和算力
3.3 CPC
原文名称:Representation Learning with Contrastive Predictive Coding。
2019年 CVPR ,Aaron van den Oord cia 8012 Google DeepMind(QS 290)

3.3.1 核心思想
- 通用性:序列、图像、音频……
- 个体判别任务 -> 预测任务
3.3.2 技术细节
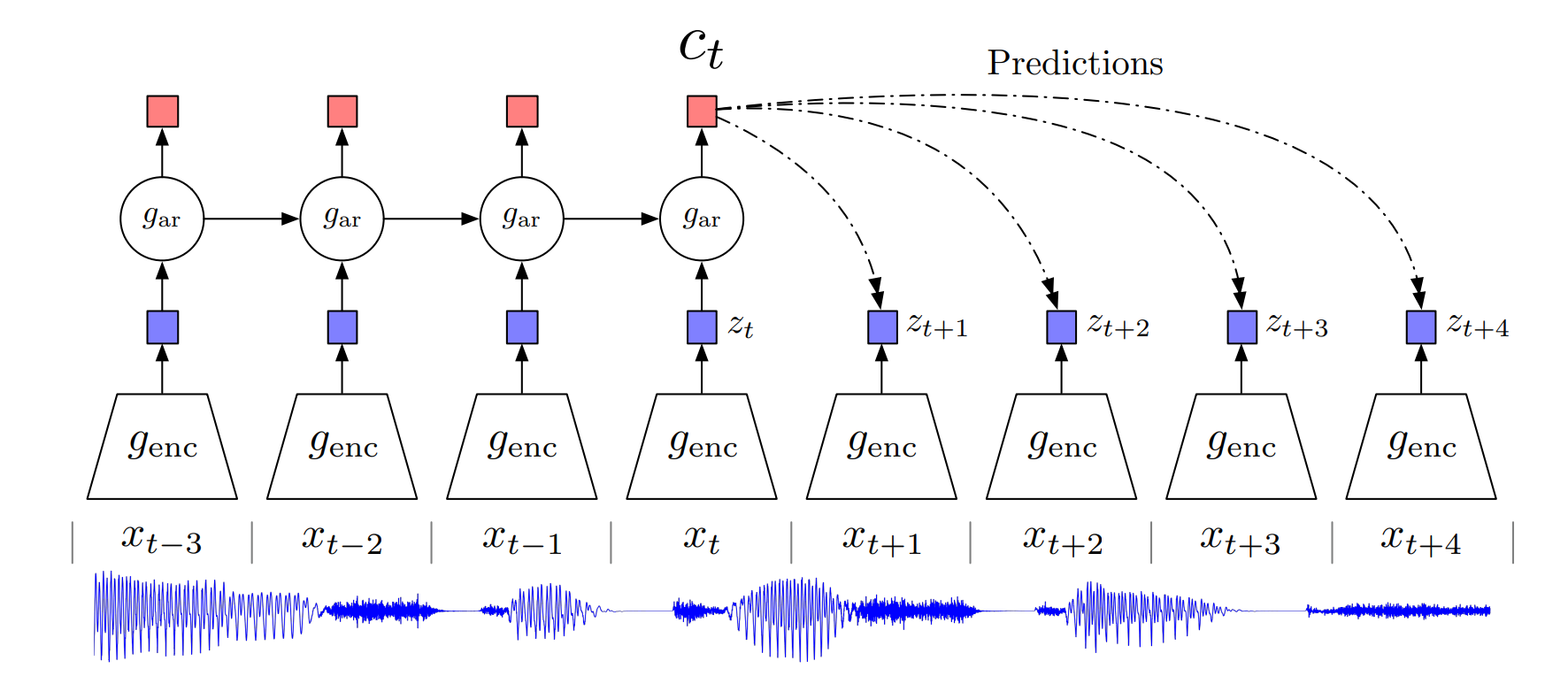
- 正负样本的定义:正样本是未来输入通过编码器的输出,z t+ 1 2 3 ……,负样本就是任意的输入经过encoder的东西
- 通用型模块,可用于图像、音频、文字,可用于RL中
3.3.3 意义
- 通用性强
- 序列模型与CL的早期尝试,创新性强
3.4 CMC
原文名称:Contrastive Multiview Coding
2019年CVPR,Yonglong Tian, cia 2290,MIT

3.4.1 核心思想
- 重点想要改进数据增强的方法
- 多视角:叫声、视觉、味道
- 增大所有视角的互相关信息,从而提取出一种普适的关键特征
3.4.2 技术细节
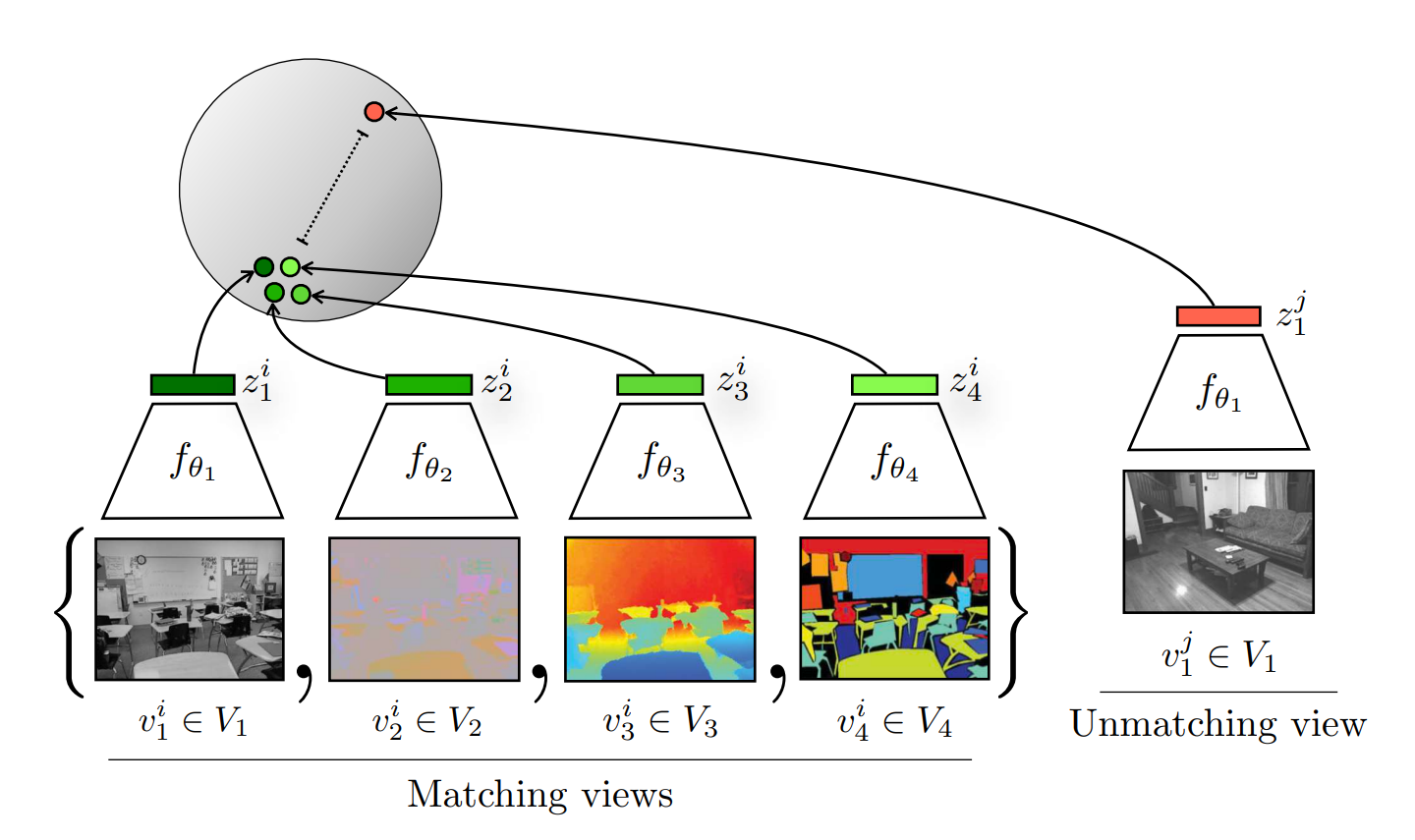
- 定义正负样本的方法:图像的多种视角正样本
- 不同视角可能要用到不同的编码器,比如Bert、VIT
- transformer具有通用性,可以处理CV、NLP多视角
- 多模态对比学习,图像和匹配的文字之间就可以做成正样本,不匹配的做成负样本
- 蒸馏任务,teacher、student之间也可以进行对比学习,同一样本输出应该类似,然后其他的负样本进行对比学习
3.4.3 意义
- 从多视角角度分析对比学习
- 数据增强的最早尝试
- 扩展了正样本的定义
- 把CL引入到了多模态、蒸馏
- 直接导致了clip模型的产生
- 使大家意识到CL的普适性
3.5 MOCO
原文名称:Momentum Contrast for Unsupervised Visual Representation Learning。
CVPR 2020 ,Kaiming He,cia 10716,Meta AI

3.5.1 技术细节
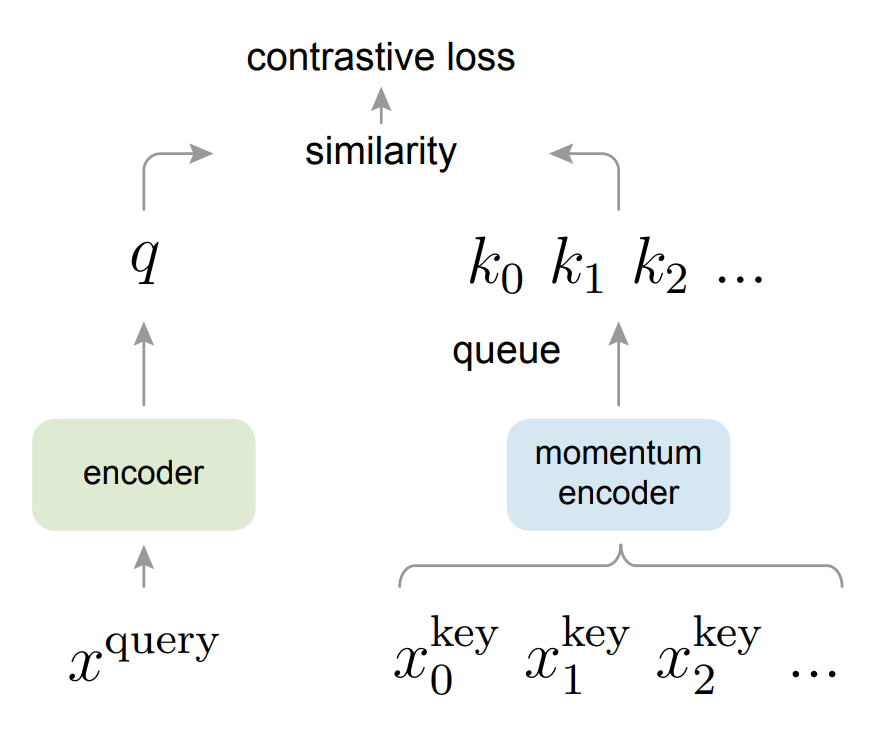
- 正负样本的对比归纳为字典查询问题
- 用队列数据结构,存储负样本,解决大字典问题
- 动量编码器,字典特征不用动,编码器动就可以,解决字典特征不一致的问题
- 使用info NCE,超参数和Inst 保持一致
3.5.2 写作细节
一种写作思路(正常但普通):引言介绍对比学习是什么,然后之前工作有哪些,然后缺点局限性,提出MOCO,解决了什么问题,最后结果很好,证明了……。
这篇文章采用自顶向下的写法,介绍中,先写CV、NLP之间的区别,为什么无监督学习在CV的问题原因。之后在CV、NLP统一框架下,归纳为字典查询问题,在这种情况下进行介绍对比学习。最后,引申自己的主要工作:希望用字典……。
方法部分:定义目标函数,正负样本,网络结构,实现细节和伪代码(为了普适性,输入输出没有限定,编码器之间share也都是可以的)。
这种写法写的很大,别人可能看不懂。
3.6 SimCLR
原文名称:A Simple Framework for Contrastive Learning of Visual Representations。
ICML 2020,Ting Chen,cia 15622

3.6.1 技术细节
(2, sequence_length, 512) (2, sequence_length, 512)
(1, 3, 26) 1,2,3 -> a, b, c
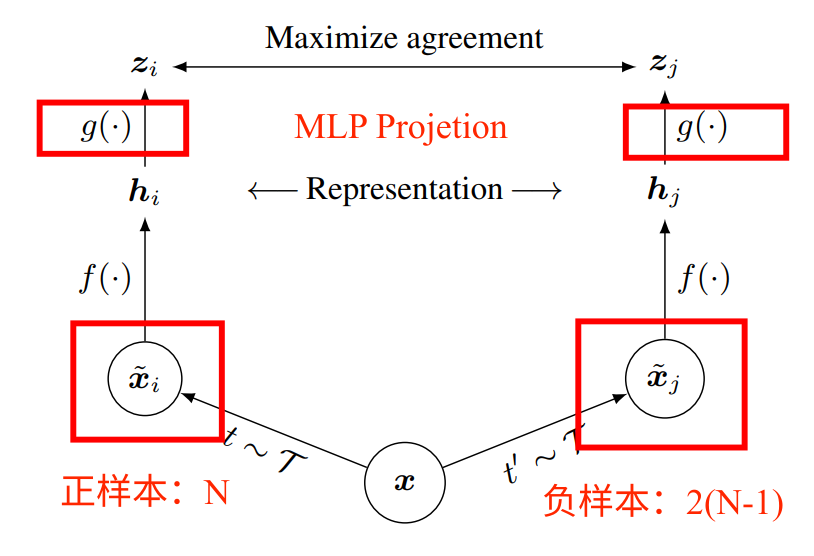
- 简单易懂
- batch_size很大,4096
- f是编码器,两个f共享权重
- MLP提点10(Linear、relu)
- g函数只有在训练的时候用
- 很多的数据增强
3.6.2 实验细节
对比学习128维度就可以了。
消融实验,论证了图像任务中,众多数据增强的方式对于结果的不同影响。
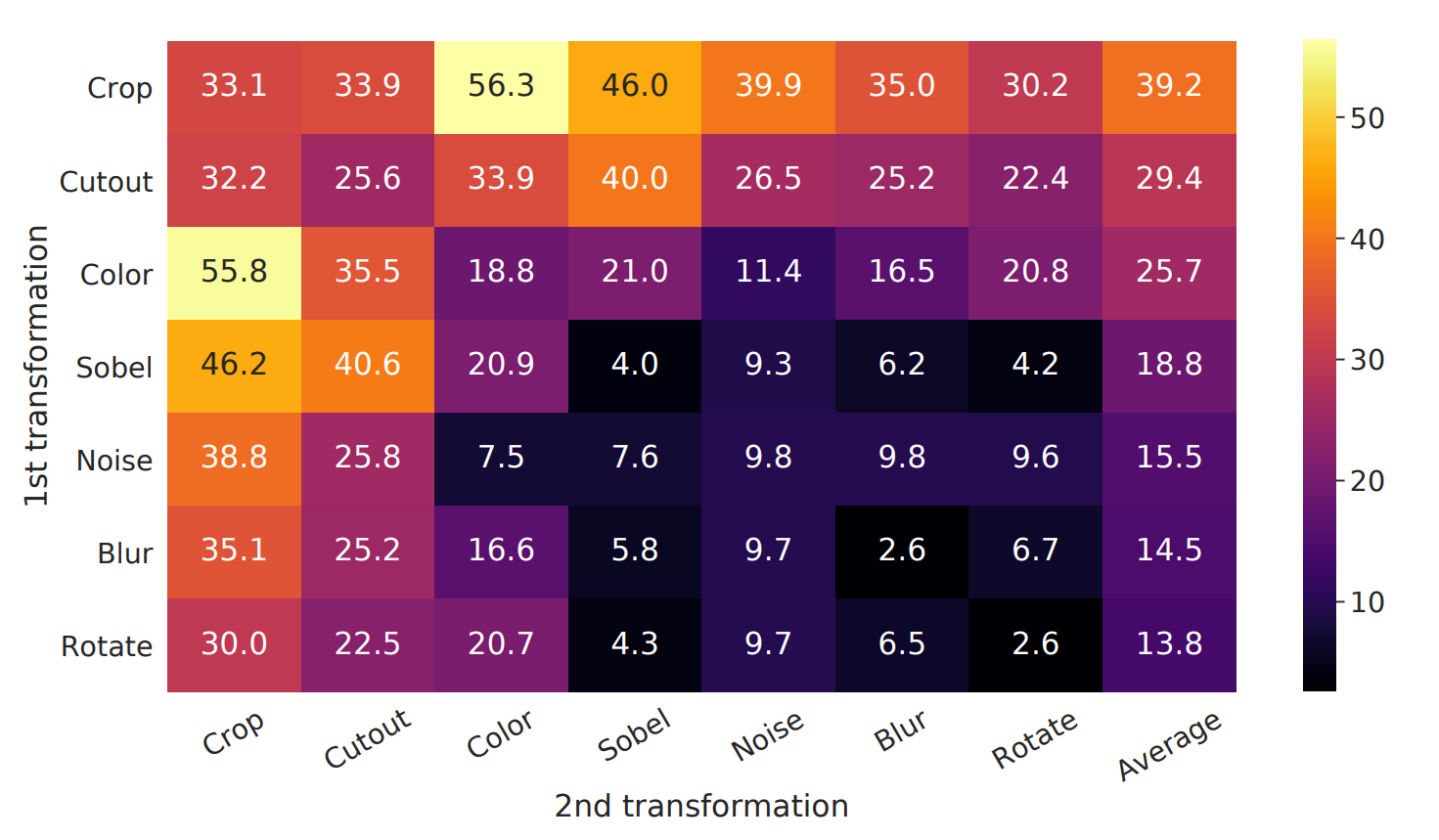
3.6.3 意义
- 总结之前的工作,并且清楚的表明一些做法的好处和概念,这也是一个好工作。
- 同时,数据增强策略、MLP Projection、large batch_size 等训练上的技术很有价值,对后面的工作产生了较大的影响力。
- 效果很好,却又简单
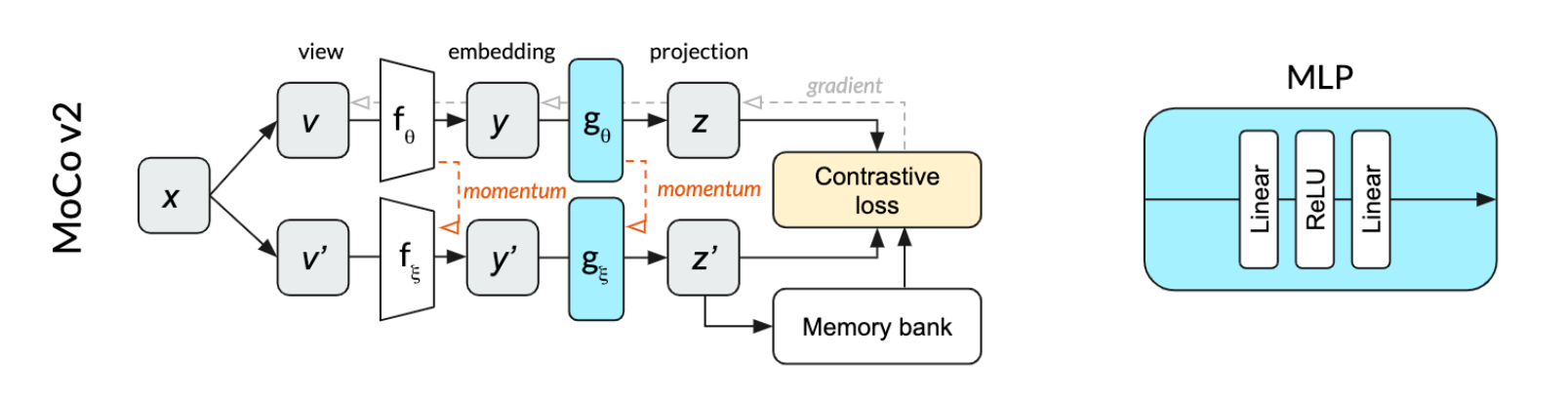
3.7 MOCO V2
技术报告:Improved Baselines with Momentum Contrastive Learning
3.7.1 核心思想
使用simCLR上的技术看看效果
- 使用MLP Projection
- 使用数据增强
3.7.2 实验结果
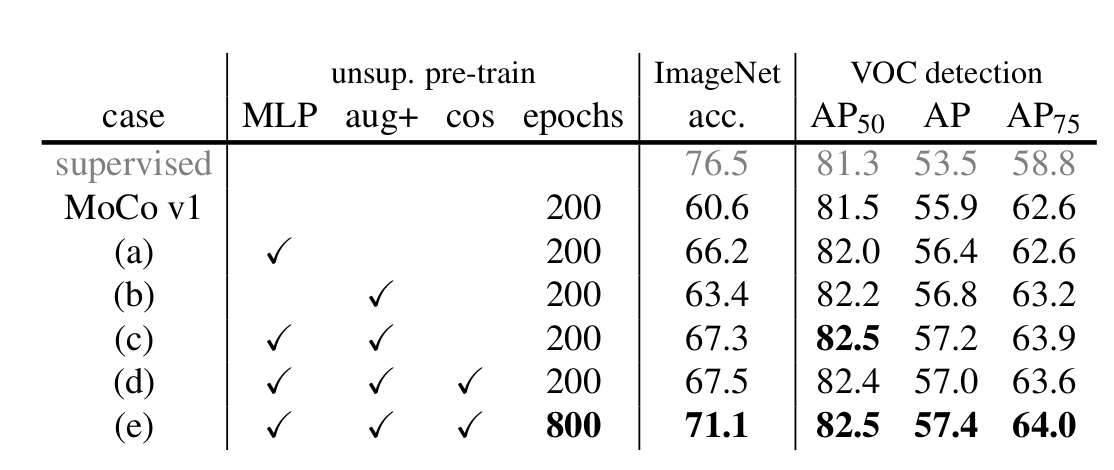
3.7.3 技术细节
需要8张 V100
3.8 SimCLR V2
原文名称:Big Self-Supervised Models are Strong Semi-Supervised Learners。
NIPS 2020,Ting Chen,cia 2130
3.8.1 技术细节
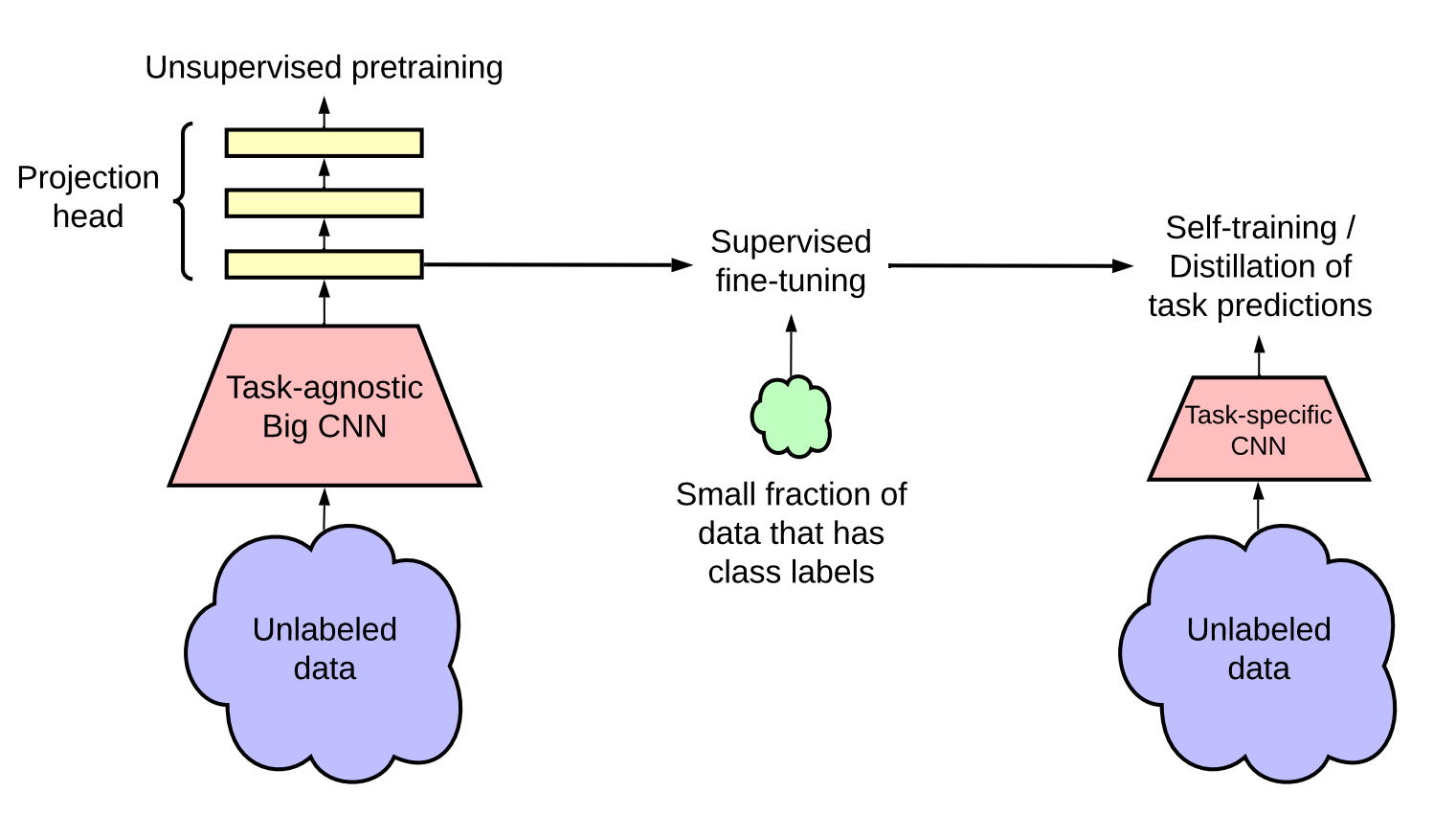
- 重点介绍了预训练 & 微调,teacher & student(半监督)的细节总览
- 更大模型( ResNet70 -> ResNet 152 + SK(selective kernal) )
- MLP更深的研究(发现两层效果很好)
- 使用了动量编码器(确实有用的)
3.9 SwAV
原文名称:SwAV: swap assignment viewsUnsupervised Learning of Visual Features by Contrasting Cluster Assignments
NIPS 2020, M Caron, cia 3419

3.9.1 核心思想
- 一个视角得到的特征,来预测另一个视角
- 和聚类进行结合:原始的对比负样本都不可能全部包含真正的负样本,都是一种近似,那么可不可以和聚类中心比较,这样更加简洁、高效?
3.9.2 技术细节
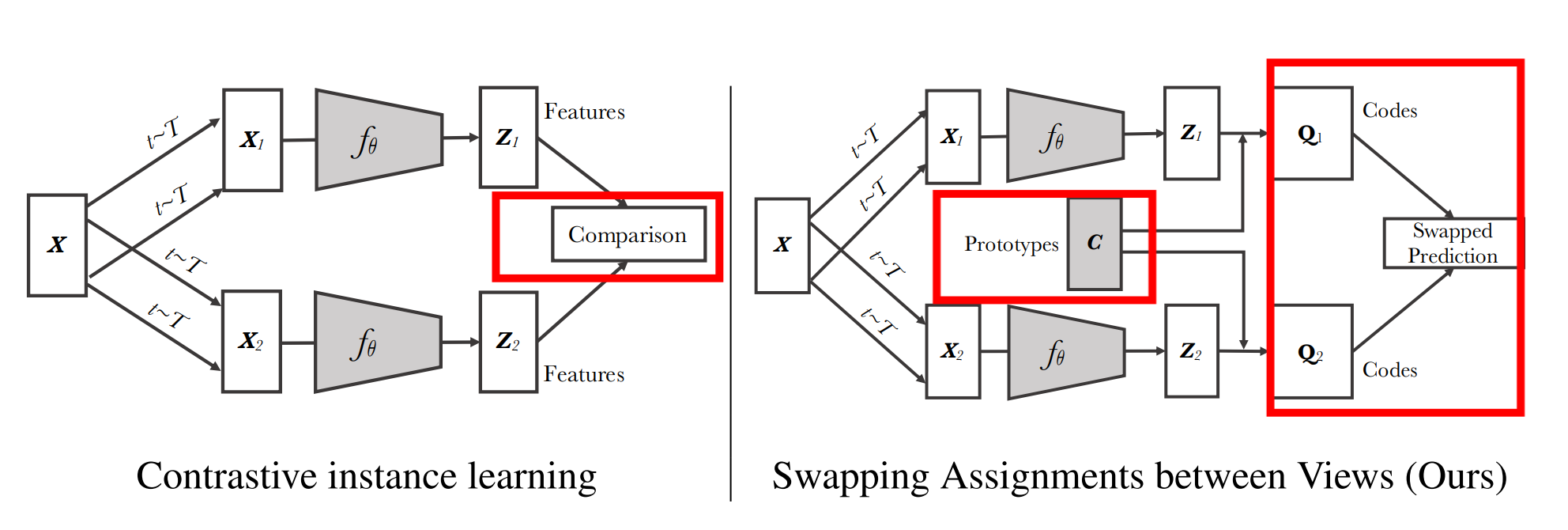
- k是聚类中心个数,k=3000,是聚类的常用参数
- 换位预测,
预测 ,反之亦然 - 聚类可以减少负样本的数量,减少数量
- 聚类中心存在明显的语义含义,可以防止负样本中出现了正样本,并且防止样本不均衡
3.9.3 结果炸裂
使用的是ResNet,达到了有监督训练的水平80。
以下是不用负样本
就是正样本和正样本自己学,左脚踩右脚上天
3.10 BYOL
原文名称:Bootstrap your own latent: A new approach to self-supervised Learning。
NIPS 2020,Jean-Bastien Grill,cia 5821
3.10.1 技术细节
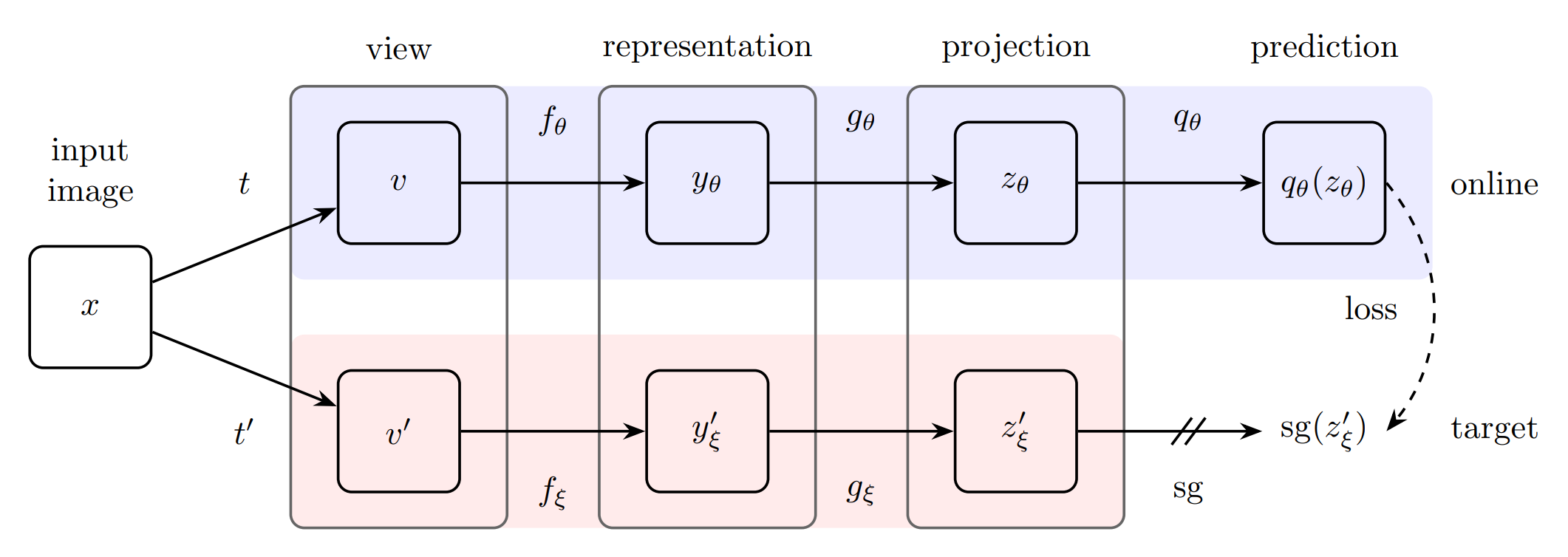
- f(上)是随梯度更新而更新
- f(下)是moving average 动量更新
- f是同一个网络架构
- 256维的
也是一个MLP,把配对问题换成了一个预测问题 - 和
有共同之处:把配对换成了预测 - 训练完成之后,只需要f就可以了,y用来做下游任务
3.10.2 插曲
博客

在复现该模型时,发现模型不仅没有达到原论文效果,并且,出现了模型的坍塌。后来发现是一个很小的区别:复现代码MLP Projection,没有引入Batch Norm。因此,这篇博客作者认为,Batch Norm起到了至关重要的作用,并且猜测,Batch Norm 在计算mean和variance 时需要引入各个样本的数据,这就暴露了各个样本的信息,相当于和平均图片做了对比。
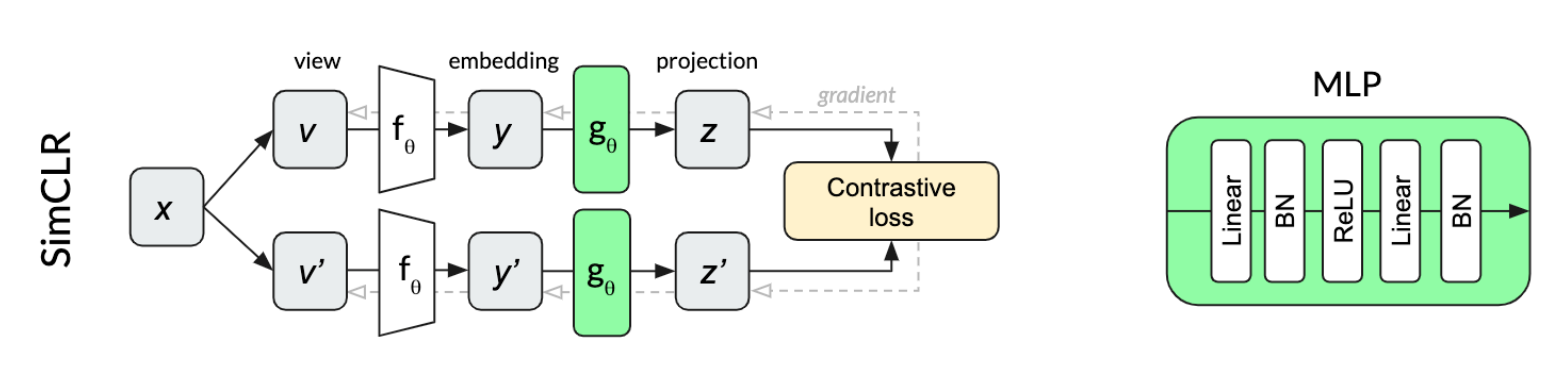
关键可能在于BN,下面是BYOL的MLP
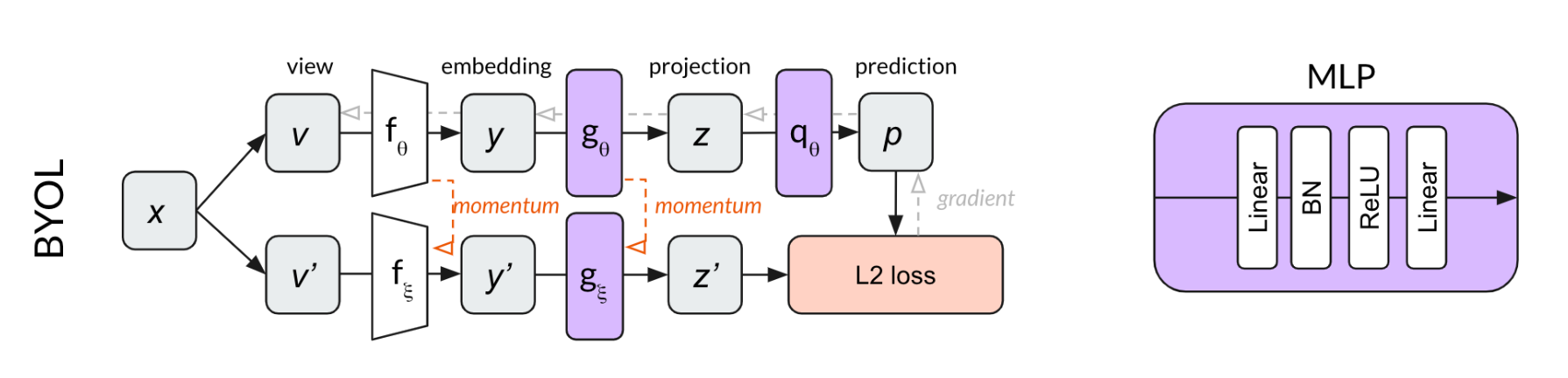
MOCO V2 的MLP如下:
博客作者做了消融实验,他的结果是
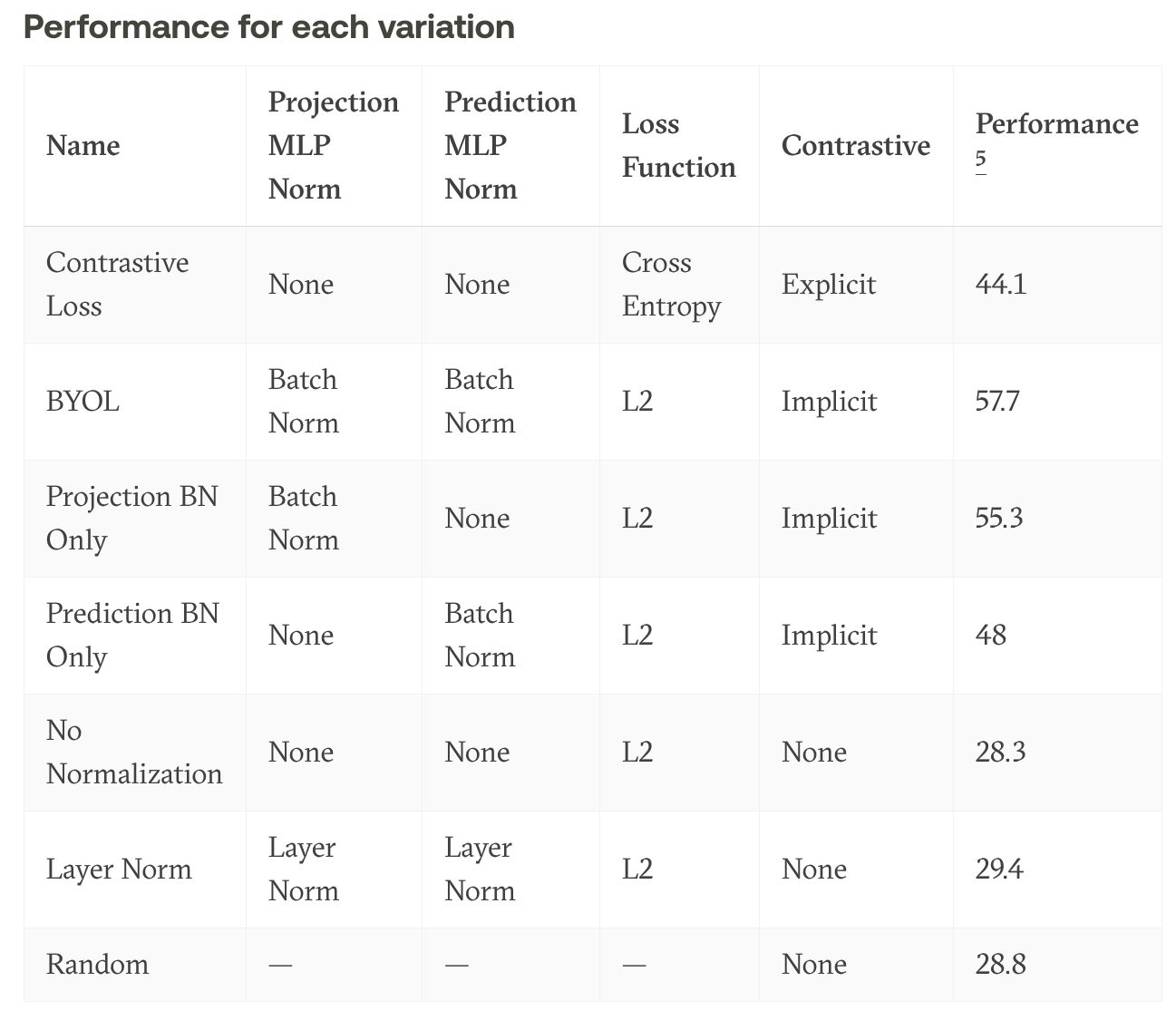
作者又搞了实验进行回应,因为如果相当于和平均图片做了对比,那么这意味着BYOL的最大创新性:不需要负样本,站不住脚。

用了BN也可能崩,并且都不用BN,simCLR也崩(这个用了负样本训练,没有predictor)
最后,作者用了group norm和 weight standardization,没有用BN,发现也可以。
所以,BN还是起到了稳定训练的作用,而不是信息泄漏。
3.11 以上总结
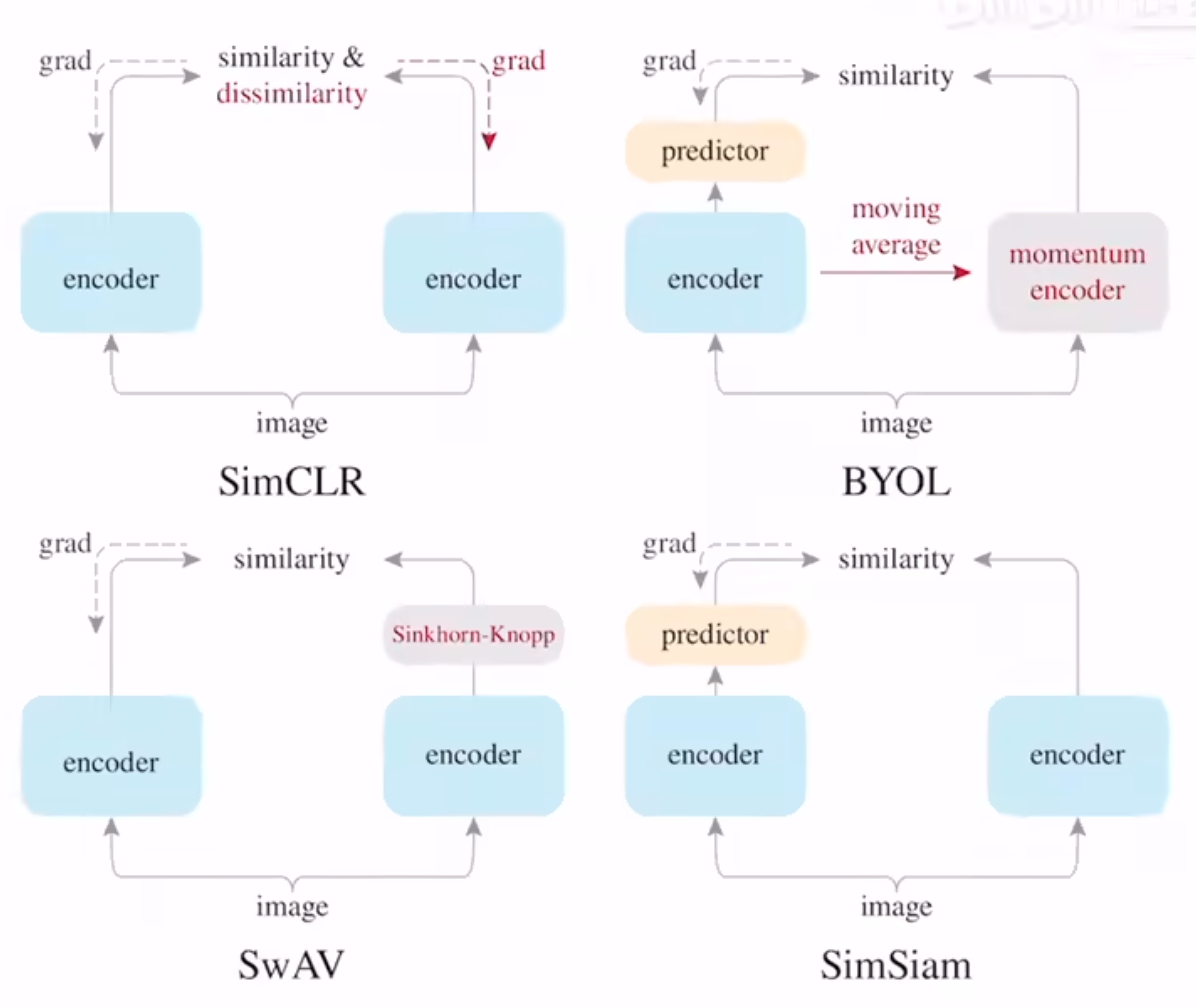
结论:
- simCLR两边有梯度回传,是端到端的任务
- SwAV 和聚类中心进行比较,有一个SK算法
- BYOL变为了预测任务,加了动量编码器
4 一些细节
4.1 损失函数
4.1.1 原始想法
交叉熵
以上拼一下:
问题在于:上式中的k指的是类别。
4.1.2
核心思想是将多分类问题转化成二分类问题,一个类是数据类别 data sample,另一个类是噪声类别 noisy sample,通过学习数据样本和噪声样本之间的区别,将数据样本去和噪声样本做对比,也就是”噪声对比(noise contrastive)“。
是一个二元随机变量,表示数据点是否来自正样本集合。
代表上下文(context) 是目标词(word)或目标嵌入(target embedding),即我们试图预测或分类的实体。
4.1.3
Info NCE loss是NCE的一个简单变体,它认为如果你只把问题看作是一个二分类,只有数据样本和噪声样本的话,可能对模型学习不友好,因为很多噪声样本可能本就不是一个类,因此还是把它看成一个多分类问题比较合理。
4.2 动量编码器
原始的大负样本流程
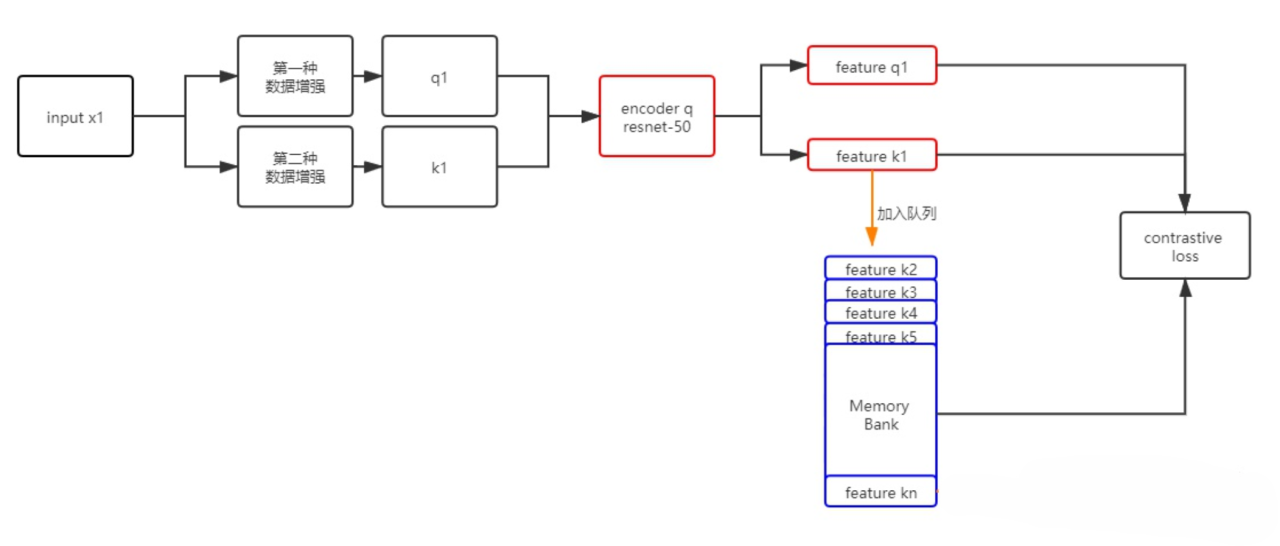
MOCO动量编码器的流程,核心改进
- 其一: dictionary->长度K的队列,每次计算loss时就用K个负样本,然后将当前batch得到的特征 k入队,队头出队,维持长度为K。
- 其二: Momentum update,因为dictionary的key来自于不同的mini-batch,通过这种方式缓慢更新(slowly progressing)key的encoder,使得key的特征保持一致性(解决了传统 Memory bank 的痛点)。
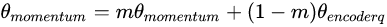
实验发现,适当增加m会带来更好地效果,因此MOCO m=0.999,也印证了缓慢更新key的encoder是使用队列dictionary的核心。
4.3 大batch_size,如何改进?
FlatNCE:小批次对比学习效果差的原因竟是浮点误差? - 科学空间|Scientific Spaces
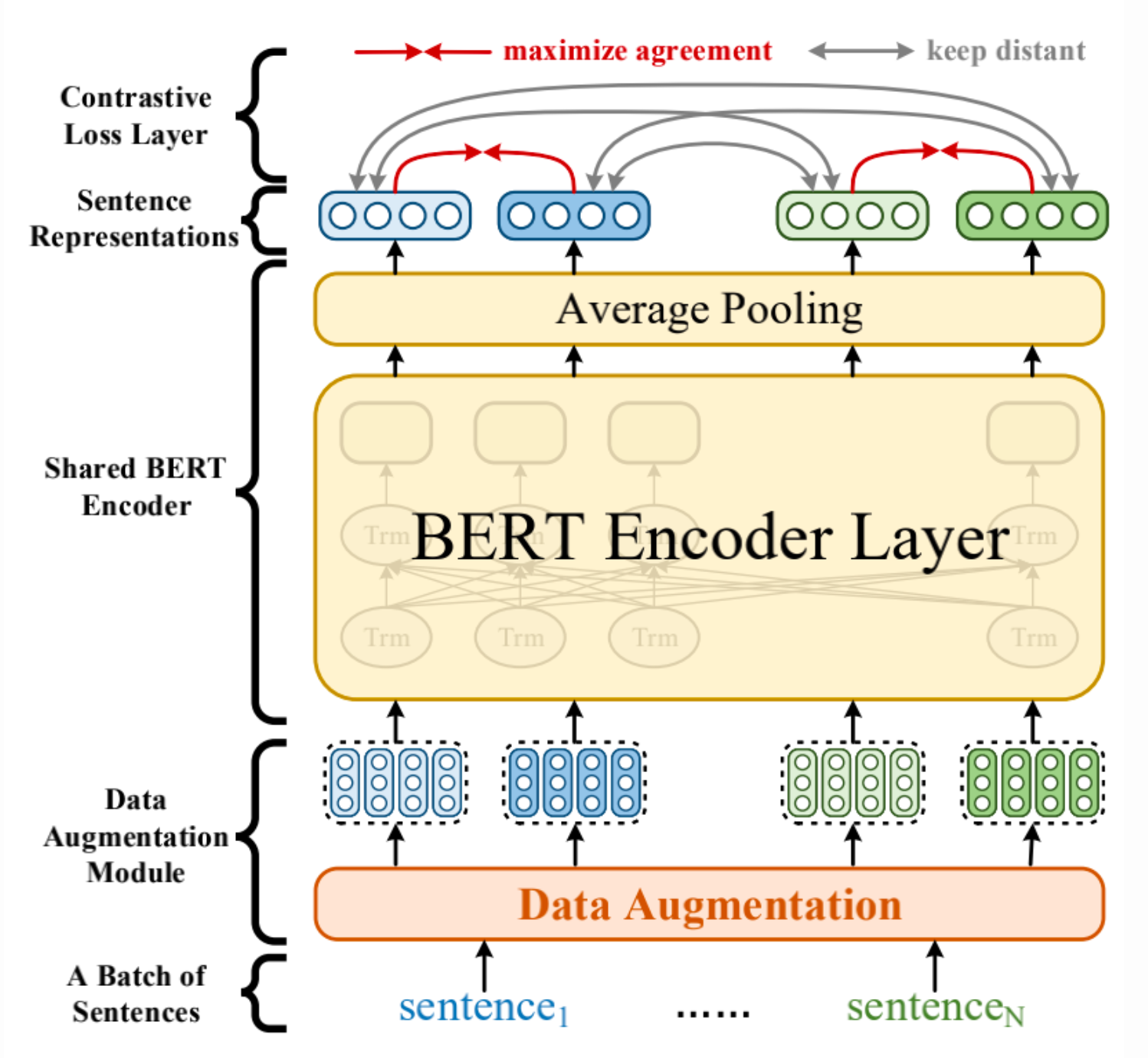
4.4 NLP的特征投影
ACL 2021|美团提出基于对比学习的文本表示模型,效果相比BERT-flow提升8% - 美团技术团队